论文阅读:《Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods》
本文内容为笔者对近期搜集的一篇综述论文的阅读,主题为大模型帮助下的强化学习。
文章来自《IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS》。DOI:10.1109/TNNLS.2024.3497992
师姐在2024年9月13日组会上讲过这篇文章,本文会适当加入师姐的汇报内容。
摘要
- 文章总结了目前已经存在的LLM强化下的RL方法,并把它们和传统的RL方法作比较。
- 系统地给LLM在RL中的作用做分类,对于每个作用都会讲LLM的应用方法。
- 信息处理
- 奖励设计
- 决策指定
- 生成器
Intro
开头先讲了过去一种把NLP和RL结合的研究,遇到了如下挑战:
- Sample Inefficiency
- Reward Function Design
- Generalization
- Natural Language Understanding
后来NLP领域进化出了LLM这样厉害的东西,LLM和RL结合,能提供一种独特的解决上述问题的方法。
文章主要做了如下贡献:
- 首次对于LLM结合到RL的研究做了一个全面的总结。
- 提出一种分类方法,来区分这些研究中LLM起到的作用。
- 对于每个分类,都会说明研究用了哪些算法,供未来研究参考。
Background
本章讲RL和LLM的一些基础知识。先讲RL,再讲RL的一些前沿发展趋势,尤其是对多模态数据源的融合,包括语言和视觉信息。再就是讲下LLM的背景知识,以及它为RL提供助力的关键点有哪些。
RL背景知识
传统RL
虽然没啥用,既然是文中插图,还是贴上来比较好
RL的挑战
目前RL有一些挑战,导致其在实际应用上受限:
- Generalization in Unseen Environment
我不太理解这个Generalization具体是啥意思,泛化?不过后面有解释,总的来说就是,现在RL模型一般是在特定的环境下训练的,训出来的这个模型如何用在一个新的、不确定更高的环境(比如实际环境),是个问题。一个在特定场景下表现良好的模型,在另一个新颖的、情况动态变化的环境下表现很难做到一样好。现实环境很少是静态或者可预测的,所以想提升模型泛化性需要模型在学习特性任务的同时,还得理解任务背后的一些原则。
我个人理解是,在这方面RL像是一个不会举一反三的学生,你教ta做一个题,ta就只会做这一道题,但是再给ta拿一道同类型的题,ta就不一定会做了。
- Reward Function Design
不必多言,做过RL的想必都能理解奖励塑形是一件多么令人头大的事。
- Compounding Error in Model-Based Planning
这里涉及有模型RL和免模型RL的概念。有模型(model-based)RL智能体通过学习状态转移来采取动作。如果用马尔科夫决策过程定义要完成的RL任务,表示为
举例:棋类游戏的环境具有规律性,可构建一个环境模型,下了某一步之后可以预见之后下不同步的各种路径,可以用有模型RL。机械臂控制、自动驾驶、空战等属于免模型RL。
有模型RL在决策过程中会有误差积累,在一些复杂环境或者高维空间中影响会很明显。现在有了LLM,它的预测能力和对顺序依赖关系的理解有助于减小这些误差。
- Multitask Learning
一是在较简单任务上学习的知识可能不利于智能体在较复杂任务上的表现,而是在各种任务学习影响下的智能体在单一任务上可能达不到最好表现。设计最优的参数共享策略是很复杂的事情。在不同任务上做知识迁移,还想没有负面干扰,是很困难的。
多模态RL
得益于CV和NLP的优势,视觉和自然语言方面的模式识别越来越强大了,多模态数据也加入了RL研究。视觉数据可以是RL智能体观测环境时得到的数据格式,在机器人和一些电子游戏控制上都有应用。智能体与环境交互时,在一些特定任务上,可以不用视觉数据而是自然语言数据。自然语言数据的用途主要有两类:
- Language-Conditional RL
智能体和环境通过语言来交互。要么任务描述是用的语言,要么动作空间和状态空间的描述是用的语言。
- Language-Assisted RL
自然语言用来促进学习,但不是学习过程的一部分。自然语言此时可以是wiki或者手册这种和任务有关的信息,也可以是对一些信息的描述,比如“别撞墙”这种描述,如果是纯RL,这种描述就得想办法用一些代码逻辑等方式表示出来。
多模态信息的融入也带来一些挑战,比如智能体如何去理解自然语言,基于视觉的奖励函数怎么设计,等等。
LLM背景知识
LLM的能力:
- In-Context Learning
- Instruction Following
- Step-by-Step Reasoning
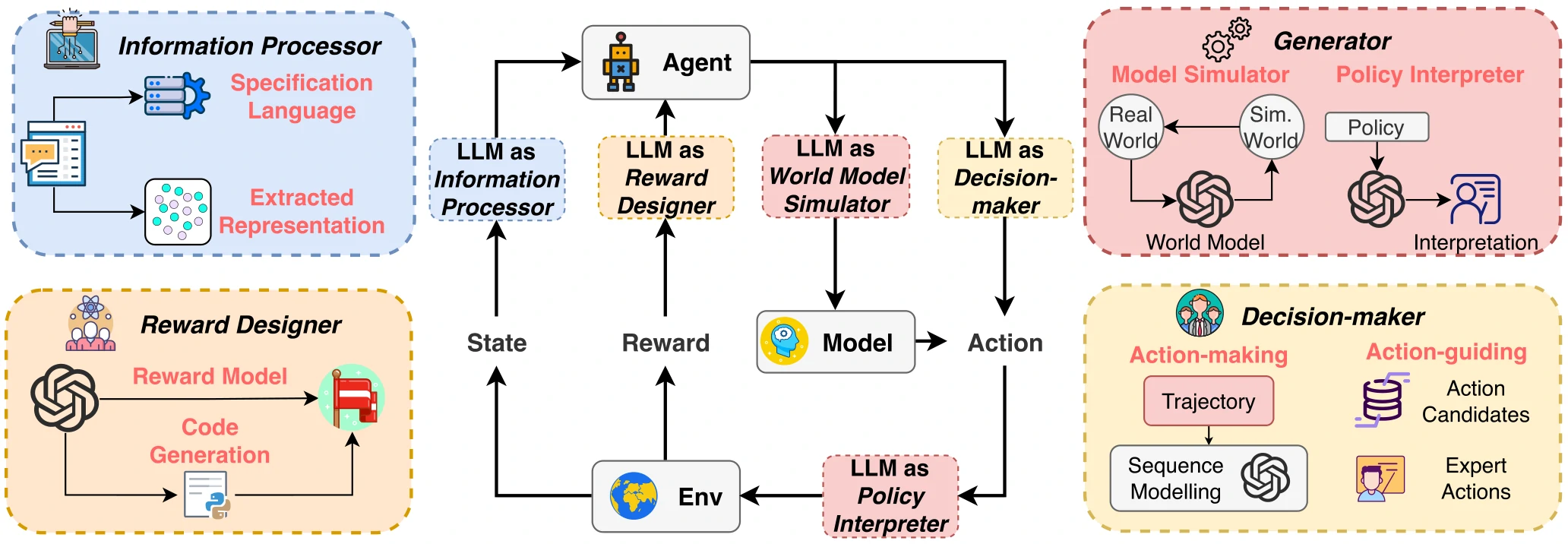
LLM-Enhanced Reinforcement Learning
本章讲结合了LLM的RL是什么概念,框架是怎样的。
LLM-Enhanced RL就是利用预先训练好的、基于知识的LLM的诸多能力来帮助RL,这些能力包括对多模态信息的处理、生成、推理,以及其他高级认知能力。
整体框架如图2所示。
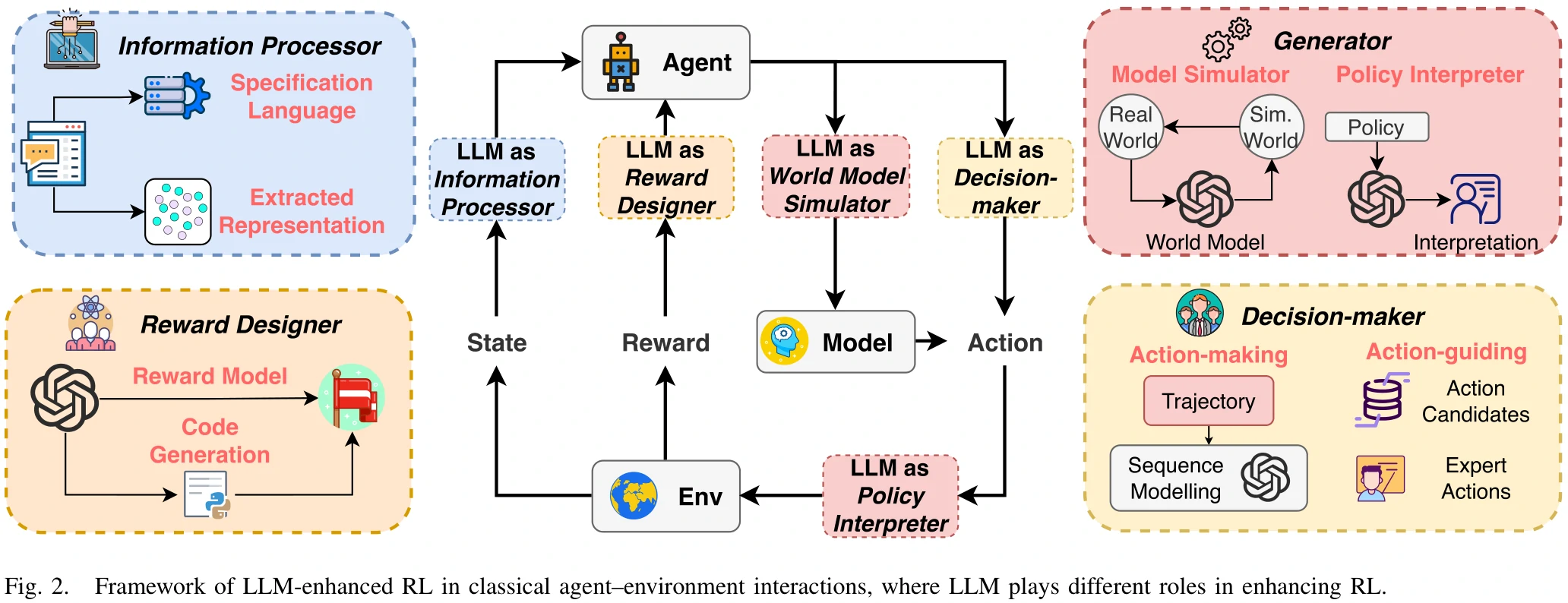
LLM-enhanced RL增强了RL在如下方面的能力:
- 理解多模态信息的能力。
- 将所学知识在多任务间迁移的能力。
- 提高对样本的使用效率。
- 将复杂任务拆解,进行长远规划的能力。
- 奖励塑形、奖励函数设计方面的能力。
LLM在RL中起到的作用
本章分析了LLM在RL中的作用,按照LLM的作用分了4个类别。
Information Processor
此时LLM的作用还可以再细化。
特征提取器
- Frozen Pretrained Model
- 直接用参数固定的预训练模型从观测
中提取信息。借用一些参数固定的预训练模型,来压缩、表示环境交互过程中的历史数据,比如在某个时间步,把之前100个时间步的历史数据输入给大模型,大模型基于这些历史数据提取出当前状态下的特征,把大模型输出的特征输入给RL过程进行学习。
- 直接用参数固定的预训练模型从观测
- Fine-Tuning Pretrained Model
- 针对一些泛化性能不高、对于特定任务支持不强的预训练模型。举例:机器人在完成基于视觉的的导航任务时,如果环境颜色发生变化,那么任务可能无法完成。
- 用对比学习(Contrastive Learning),利用对比损失函数
进行计算优化,提取出一些不受环境影响的、稳定的特征表示交给RL学习。
语言翻译器
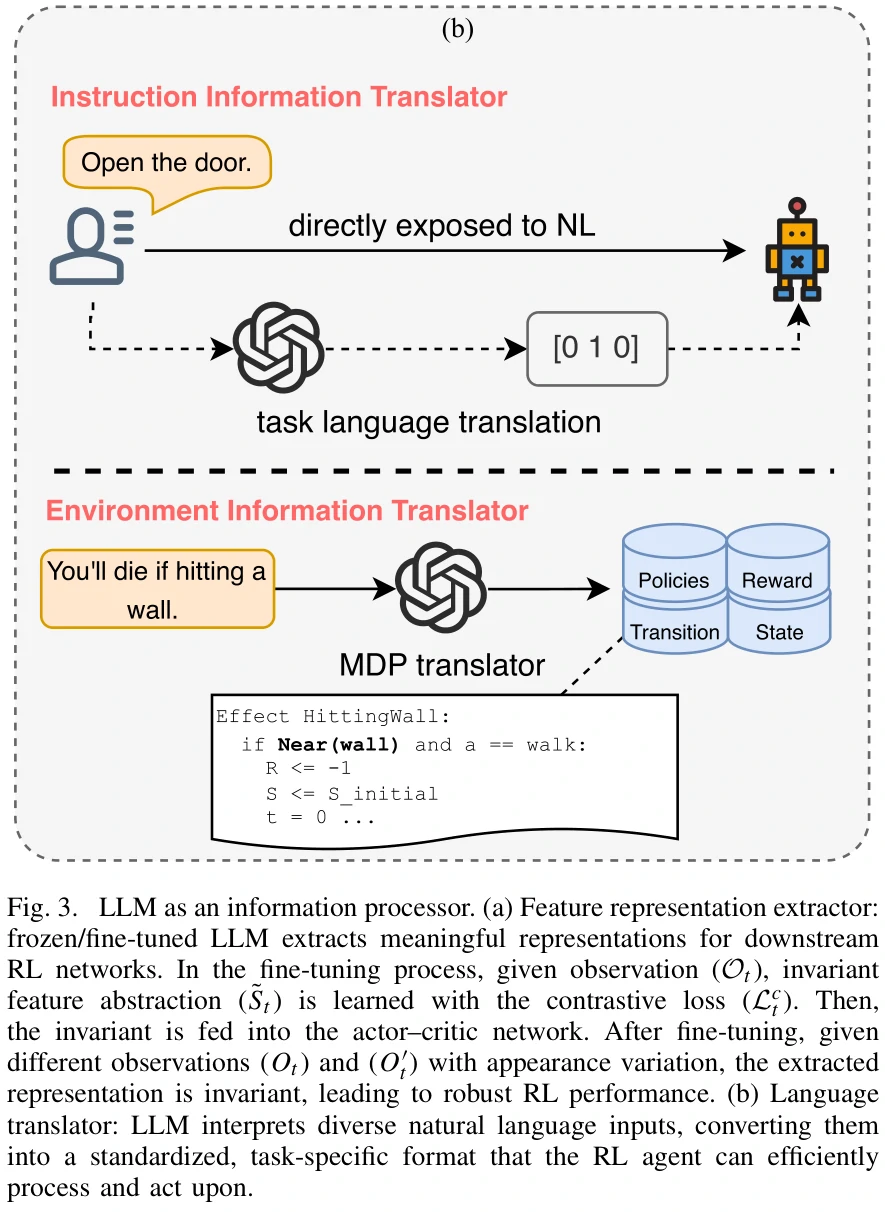
- Instruction Information Translation
- 把用自然语言表达的指令翻译成智能体能理解的语言(比如向量)
- Environmental Information Translation
- 把用自然语言描述的环境信息翻译成智能体能理解的语言(比如代码)
Reward Designer
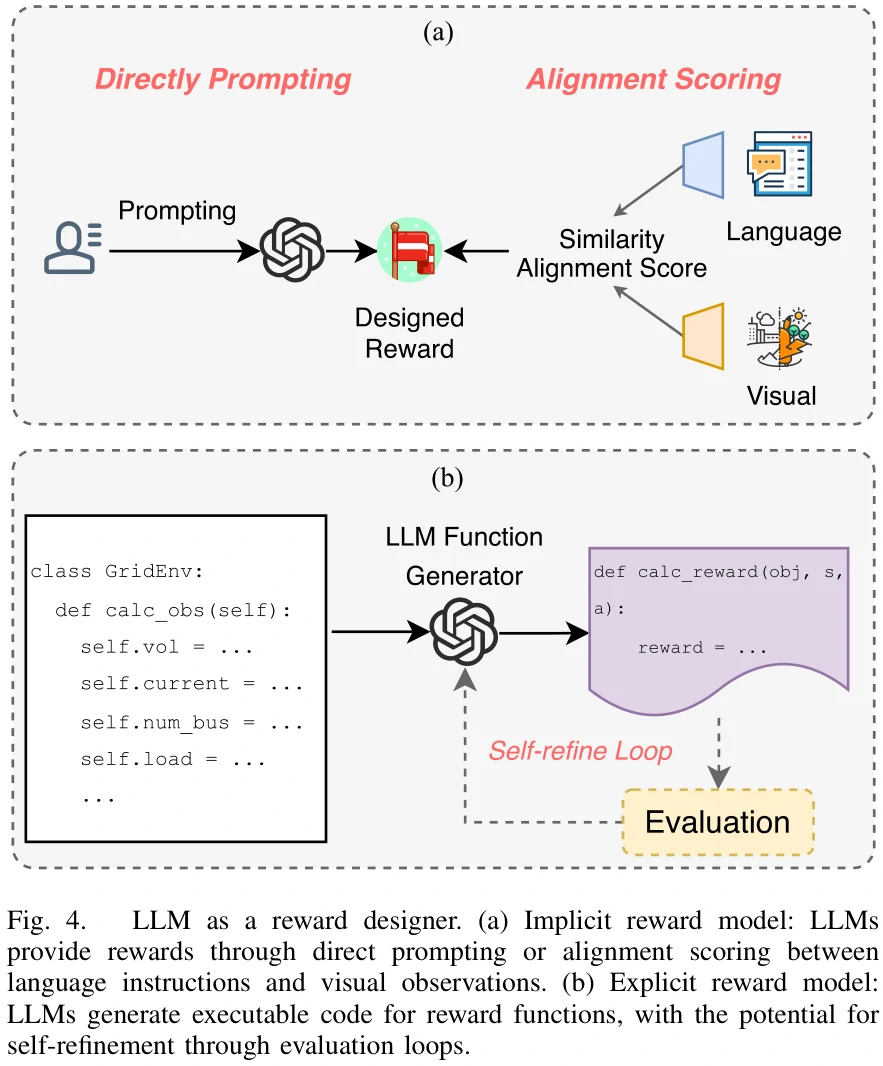
隐性奖励模型
- Direct Prompting
- 直接告诉大模型自己想要什么样的奖励,让大模型生成奖励函数。
- Alignment Scoring
- 和视觉信息有关,利用相似度对比得分,获得综合语言模态和视觉模态的信号,用于生成奖励函数。

Alignment Scoring方面,Adeniji等人针对下游任务奖励,提出一种用语言控制奖励的预训练框架
显式奖励模型
- 用高级语言指令,让LLM自动编写奖励函数代码
- 通过自我优化机制设计奖励函数,环节包括初始设计、评估、自我改进
- Text2Reward,根据环境描述生成细致的可执行的奖励函数
- 在隐性奖励模型下,生成的奖励不一定是可执行的代码,这里生成的是真正可执行的代码

Eureka设计的奖励优化算法
Decision-Maker
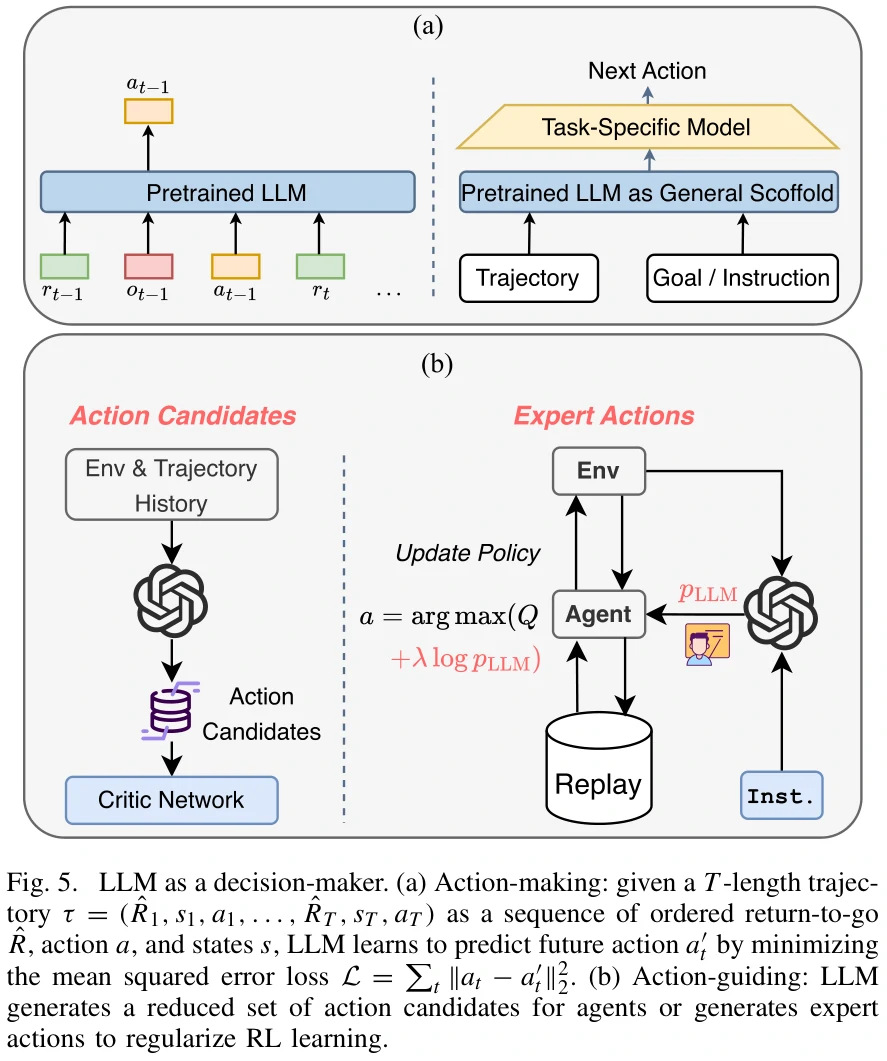
Action-Making
直接决策。直接预测下一步的动作。
- 通过Decision Transformer,用过去的行为、状态、奖励预测未来动作。
- 将强化学习看做一个监督学习问题。
- 让预训练的LLM学习不同环境中的特定任务。
Action-Guiding
间接决策,适用于动作空间大的问题。
- 生成一系列的候选动作供智能体选择。智能体计算候选动作的价值,从中选择最优动作。
- 提供参考策略,影响模型的策略更新过程。
Generator
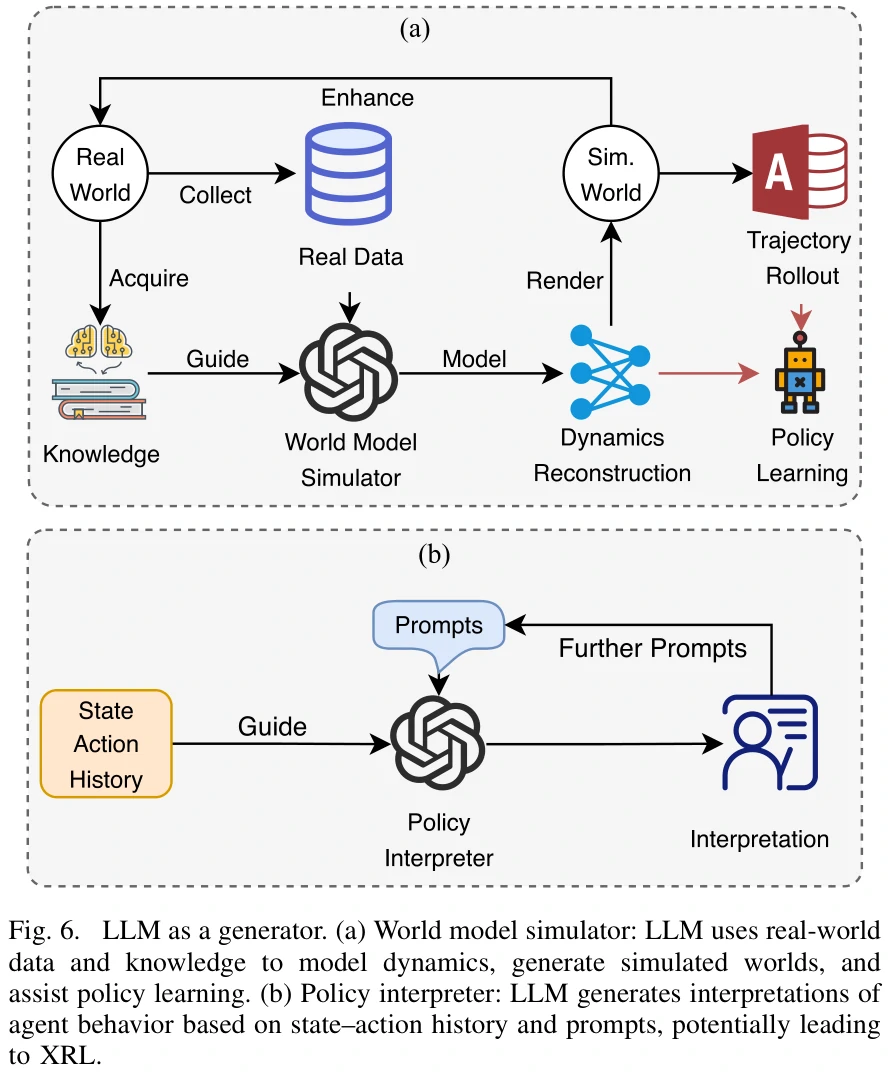
World Model Simulator
- 轨迹生成器(Trajectory Rolloutor)
- 让AI模拟未来的行动序列(轨迹),让智能体“提前预演”未来的动作。
- 动态表示学习器(Dynamics Representation Learner)
- 通过学习未来的潜在表示来做出更好地决策。

Lin等人提出的一种算法,让智能体在多模态世界模型中学习,预测未来的文本和图像表示,并指导决策过程
Policy Interpreter
可解释强化学习(XRL):结合可解释机器学习和强化学习,目的是帮助理解智能体如何做决策。包含如下类别:
- 特征重要性:找出对智能体决策最重要的输入特征。
- 学习过程和MDP:解释智能体在学习过程中所经历的状态和行为。
- 策略层面解释智能体如何基于当前策略做出具体决策。
针对LLM-Enhanced Reinforcement Learning的讨论
本章讨论LLM-Enhanced RL的应用、前景、挑战。
不同方法的对比
LLM在研究中起到不同作用,会带来不同的优势和限制。
- Information Processor
- LLM处理复杂多模态输入数据很出色,提高了智能体理解复杂环境并与其交互的能力。
- 存在计算效率上的挑战,而且需要预训练模型有相关的专家领域知识。
- Reward Designer
- 提高奖励设计的客观性,提供一种在复杂与稀疏奖励环境下设计奖励的方式。
- 需要确保设计出的奖励是符合任务目标的。
- Decision-Maker
- 提高智能体学习效率与探索能力,在需要长远规划的任务中更有效。
- 如何做到实时决策是个大问题。
- Generator
- 提高智能体对样本的使用效率,让RL过程更加清晰易懂。
- 需要思考如何让生成的模拟世界与真实世界在物理规律上一致,且保证二者的相关性,保证对策略解释的准确性。
Applications
论文只列出如下应用场景:
- Robotics
- Autonomous Driving
- Energy Management
- Healthcare Recommendation
Opportunities
- 目前LLM参与下的多智能体RL还有相当大的研究空间。
- LLM可以通过外部知识源和不断地学习来进一步加强自己。
- LLM指导下的智能体有些模块可以反过来加强LLM。
Challenges
- LLM的能力影响LLM-enhanced RL的整个过程,比如LLM可能出现的幻觉现象要怎么处理,LLM输出的内容不正确的话要怎么办。
- LLM想用在特定任务上,得给它相应领域的专家知识。涉及对LLM的微调。
- LLM的思考过程不可避免地会增加RL过程中的时延,如何解决。
-其他问题,比如伦理上的、安全上的问题。
思考
除了Generator中的Model Simulator,在其他作用方面,LLM似乎都有机会来帮助RL解决空战领域问题。
举例:
- 飞机集群对战下,让LLM辅助提取复杂状态的特征。不管飞机增加多少,让大模型输出的状态特征数据维度固定下来。
- LLM替代策略网络来输出决策。
- LLM提高策略可解释性。比如在集群多智能体空战下,任务如何规划,指令如何发送,等等。
- 一个较为具体的实操案例,2023年的一篇论文。
目前接触到的论文和其他人实操中,都没有解决LLM带来的时延问题,需要进一步思考。目前缓解时延问题的一种思路是,不让LLM参与到需要频繁处理的环节,比如动作决策等,而是让其参与训练开始时的一些预备工作,比如生成决策树之类的。
