论文阅读:《Large Language Model Guided Reinforcement Learning Based Six-Degree-of-Freedom Flight Control》
本文内容为笔者对近期同学分享的一篇论文的简单阅读。
文章在飞机飞行控制的强化学习训练过程中,尝试将大语言模型作为DRL的先验知识,以此应对纯DRL过程的弊端,并减少训练时间。
文章来自IEEE Access。DOI: 10.1109/ACCESS.2024.3411015
序言
序言部分简要说明了文章做的几个贡献:
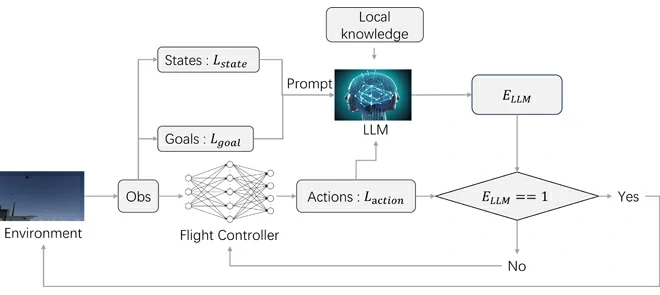
- 提出一个LLM指导下的DRL框架,LLM在训练过程中会提供直接的指导。LLM提前喂了像飞行手册一类的知识,有了评估智能体动作好坏的能力,智能体不好的动作会被拒掉,逼智能体重新做一个动作。
- 提出一个奖励函数。
- 用上述方法训练一个IFC(Intelligent Flight Controller)。
背景知识
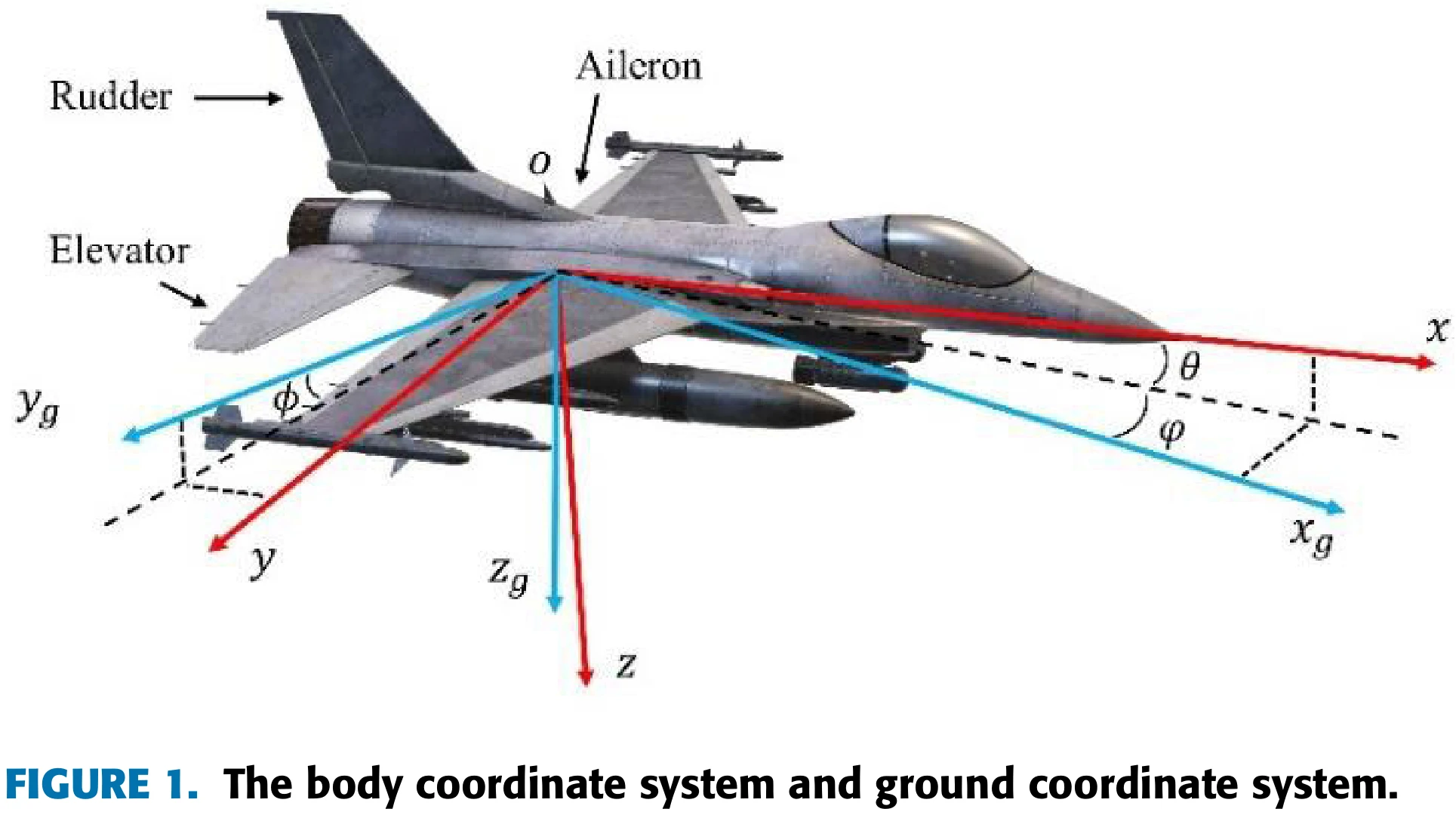
Flight Control Problem Statement
飞机是6自由度的。
Proximal Policy Optimization Algorithm
训练算法用的是PPO-clip。
文章方法
训练框架:LLM指导下的RL
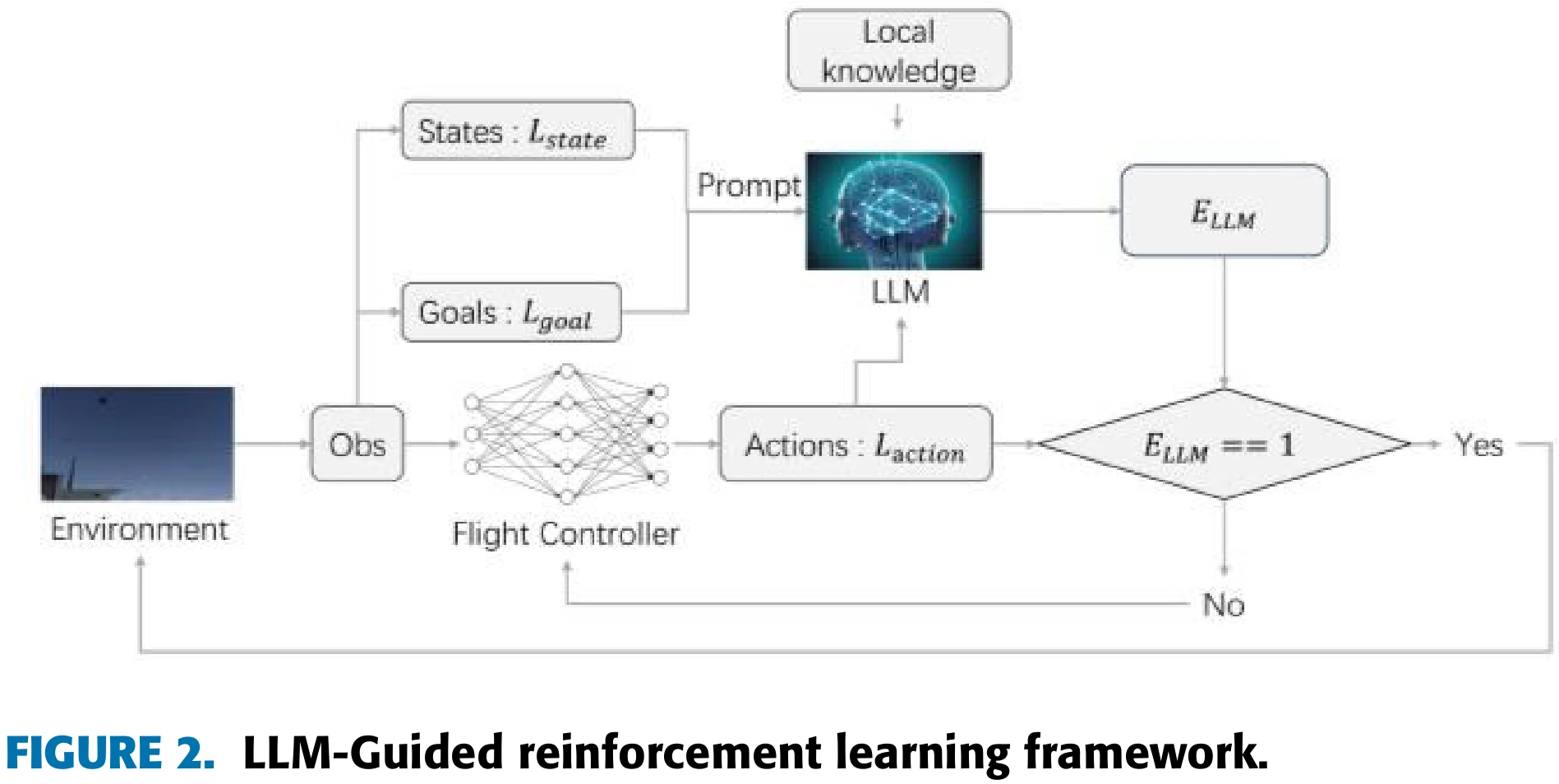
虽不影响阅读,但这些图片也太TM糊了,原图就这么糊
整个方法需要用自然语言叙述飞行器的状态、目标、动作,LLM基于状态和目标来评估动作。设用文本语言表达的状态为
LLM在训练过程中,将本地知识库中拿到的背景知识转换为动作指导信号(action guidance signals)。
LLM会回答如下问题:“当前飞行器的状态是
智能体动作有4个分量,LLM会对每个分量的正确性作出回答,然后相乘得到评估结果:
如果
训练过程中,由LLM指导的episode有阈值,episode超过这个阈值,就不再用LLM进行指导了。
文章基线LLM用的是ChatGLM-6B。

强化学习相关参数
观测空间与动作空间
设观测空间为
第一个部分包括飞行状态
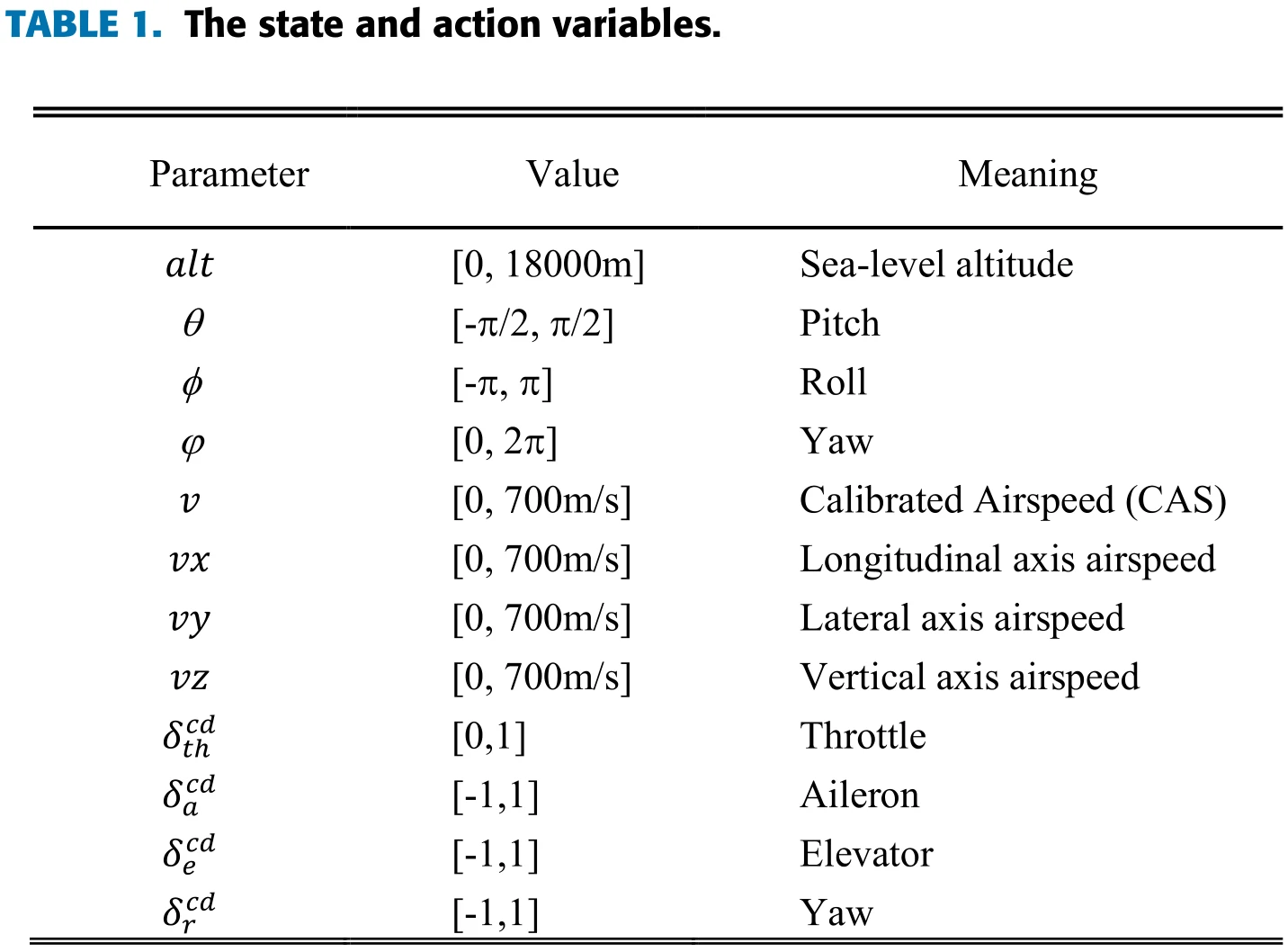
第二部分描述飞行器与目标的各项状态差异:
动作空间
奖励函数
文章用了一个基于potential的奖励塑形技巧(参考文献),设计了一个服从高斯分布的潜力函数:
奖励函数:
| 符号 | 论文中的值 | 代表的误差波动 |
|---|---|---|
| 0.25 | ||
| 1 | ||
| 3.3 | ||
| 8.23 |
对局结束信号设计
飞机的训练任务是追击一个目标信号。如果飞机在规定时间内到达了目标,对局不会结束,一个新目标会随机生成。对局在超过规定时间,或是飞机进入危险情况时才会结束。
实验分析
实验平台
实验平台基于JSBSim。
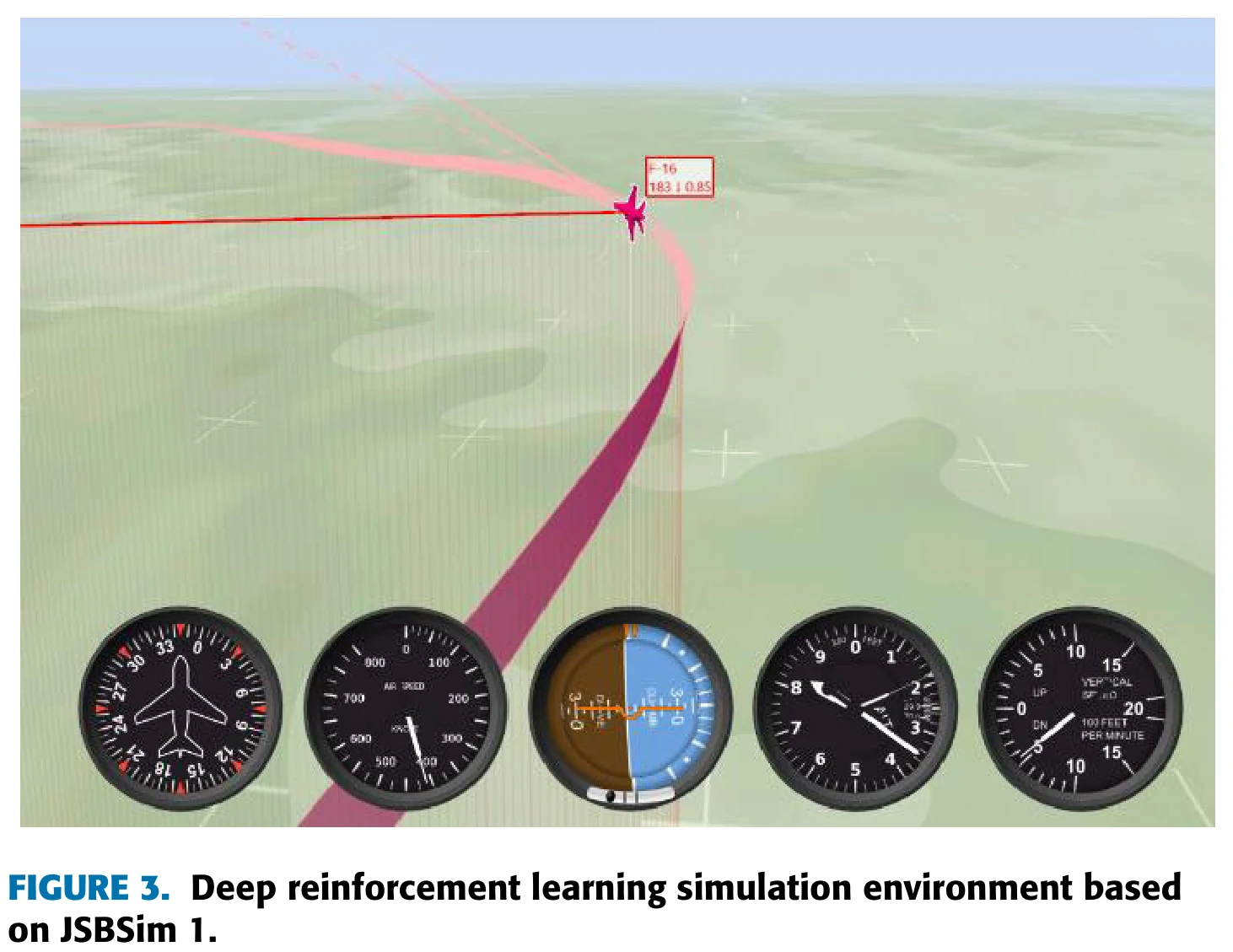

实验与结果分析
追击训练
在训练飞机追击目标的初期,文章采用Algorithm 1所述的算法,将使用LLM指导的智能体和不使用LLM指导的智能体进行对比,结果如图5所示。
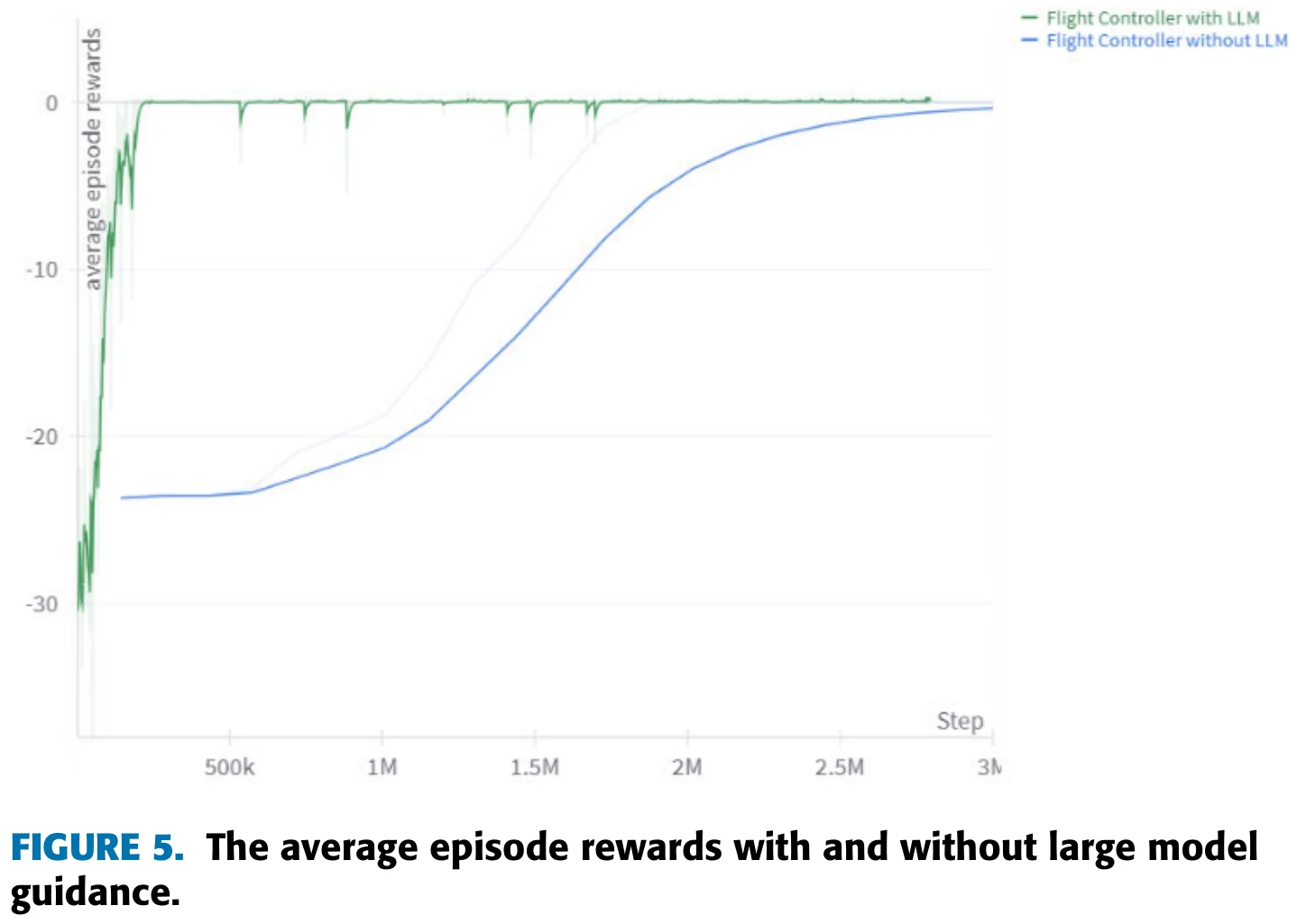
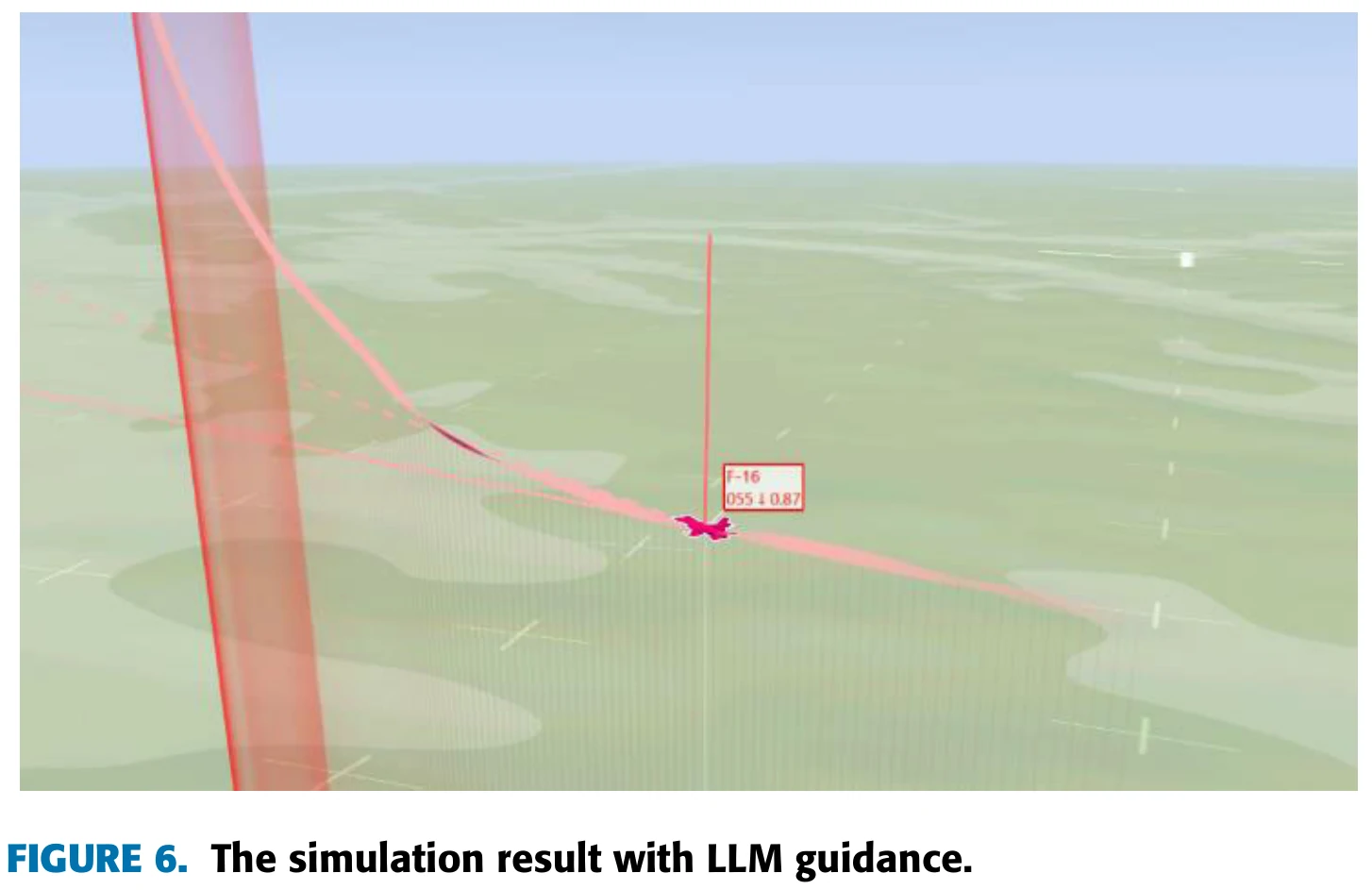
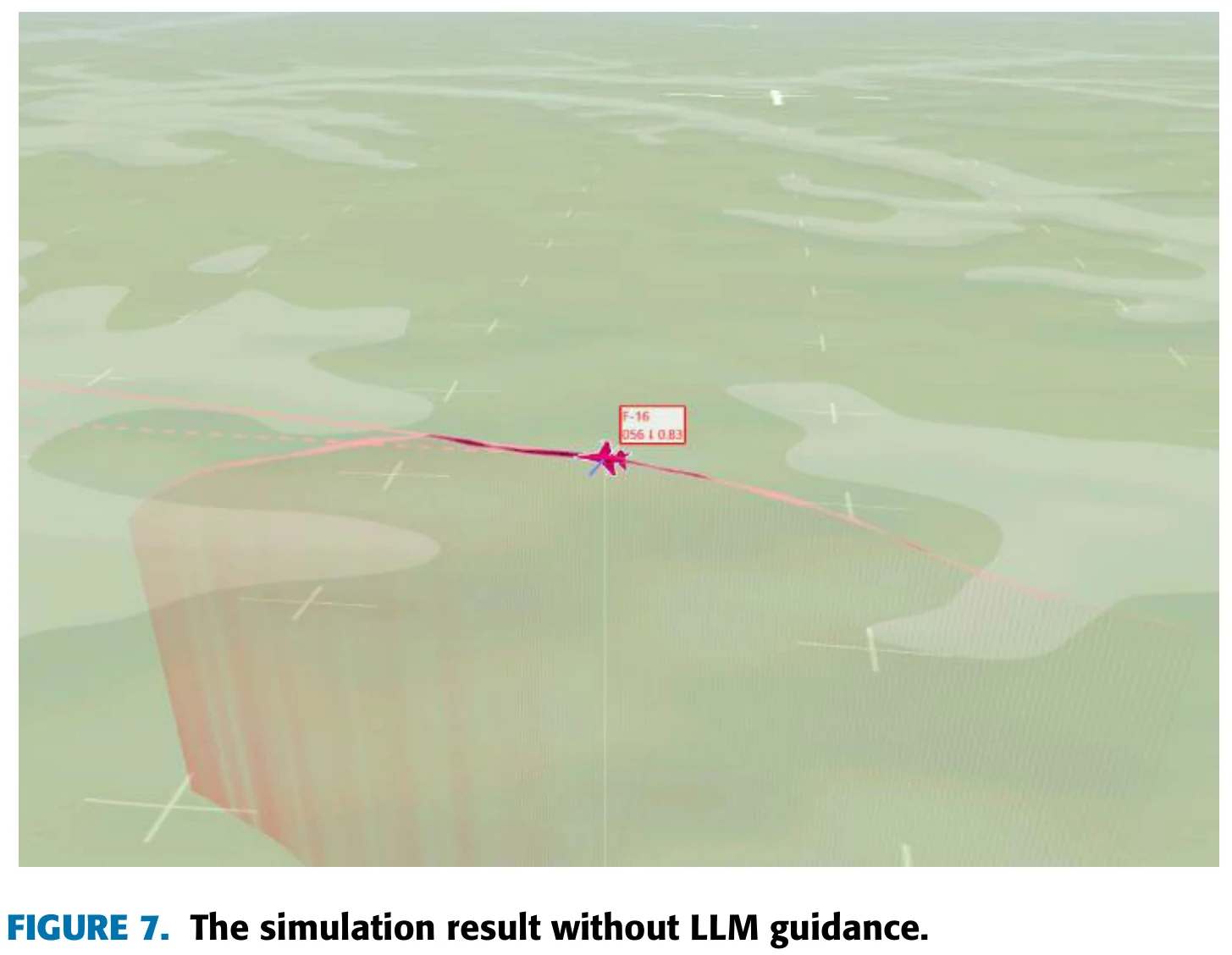
文章认为,图5说明,在LLM的指导下,智能体能够更快地学会在预期的高度范围内飞行,从而减少飞行高度过低带来的惩罚,不过此时飞机还没有学会追击目标。两种智能体在这一阶段飞行姿态的对比见图6和图7。
在令智能体学会在指定高度范围内飞行后,为了让智能体学会追击目标,文章采用Algorithm 2所示方法进行训练,目标位置的随机性是逐渐上升的,以使智能体的训练从易到难。

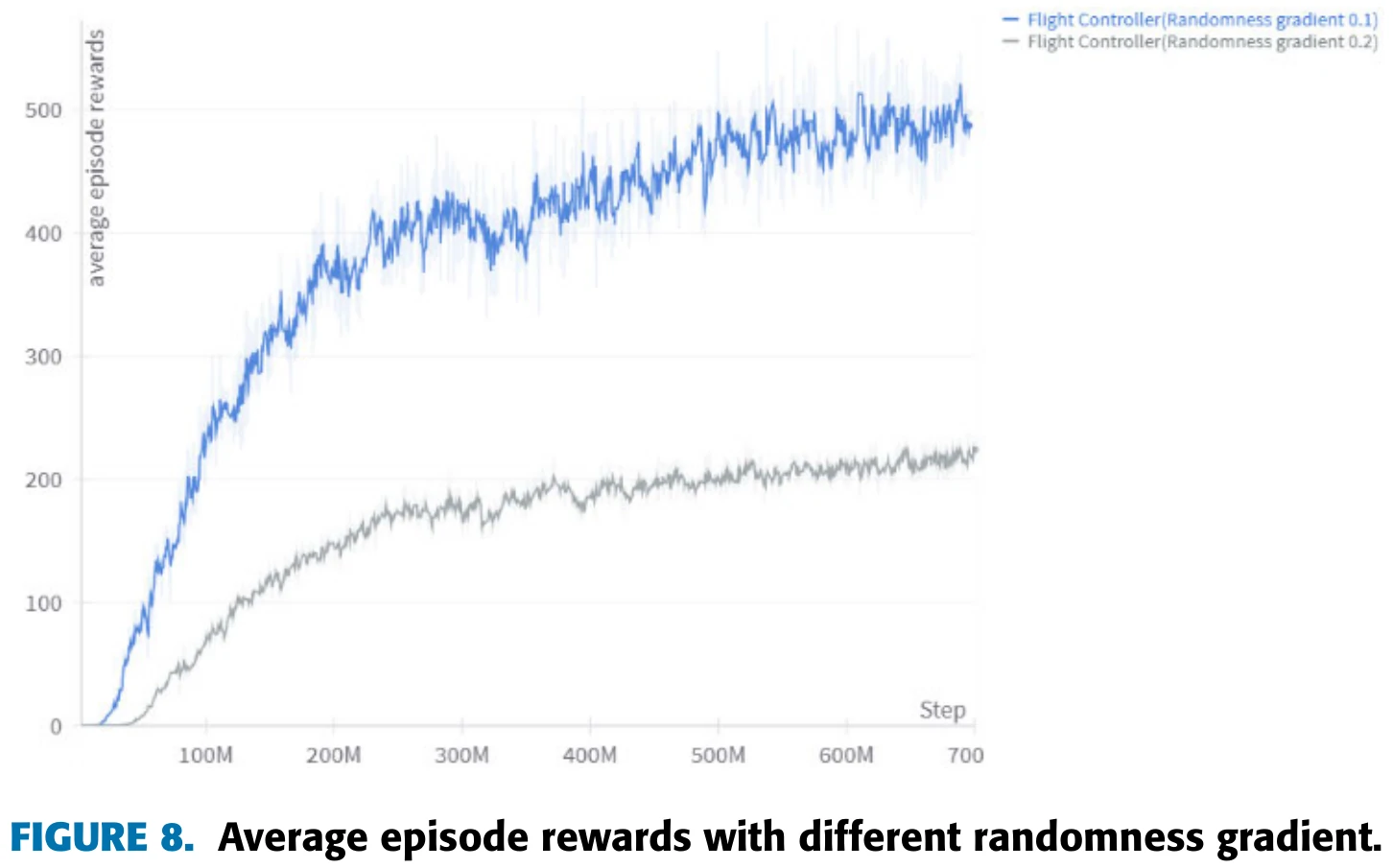
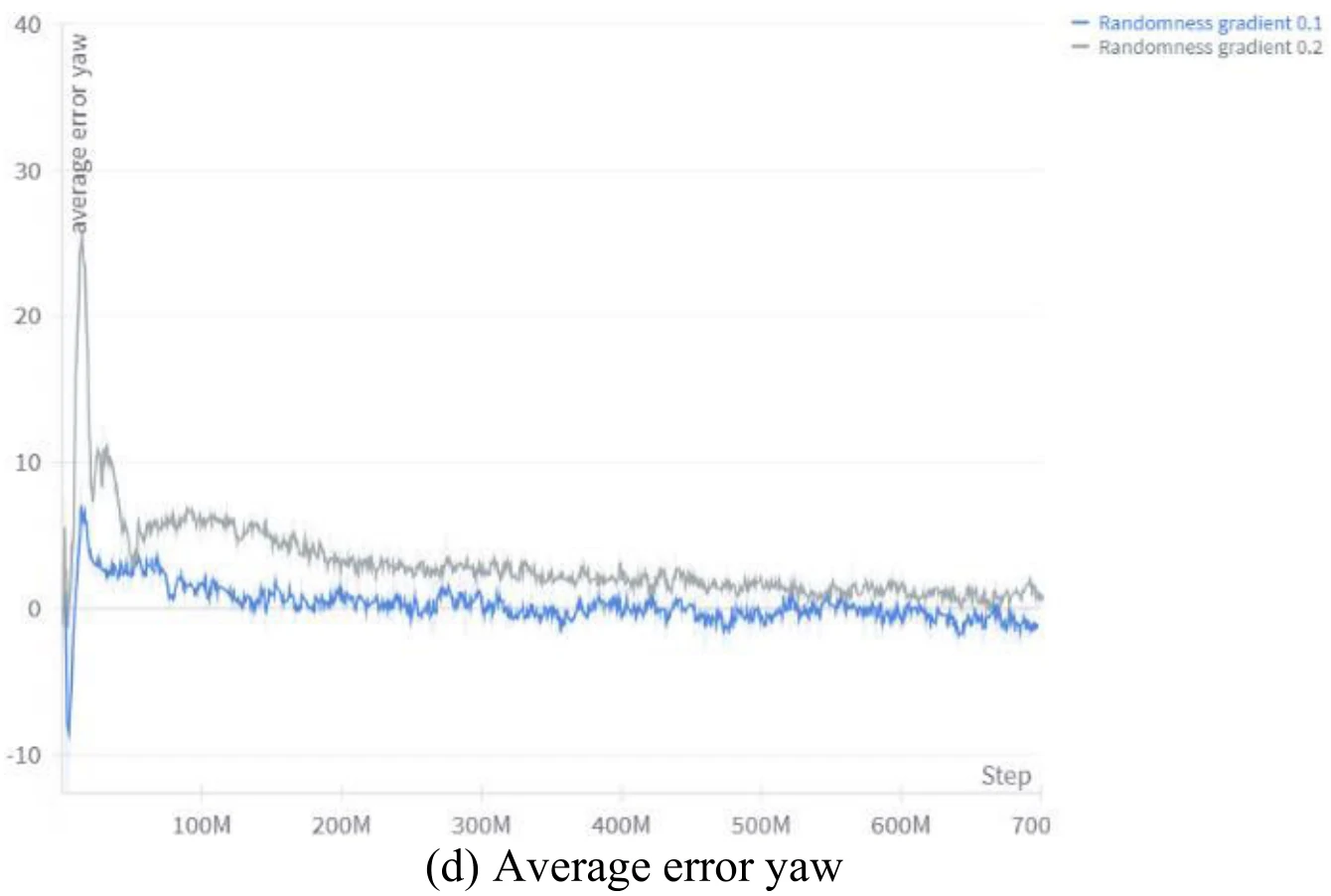
图8展示了目标位置随机性上升的梯度对于训练速度的影响。文章认为,较小的随机性提升速度让智能体更加快地到达目标,所以相同时间下的获得的平均奖励更高。
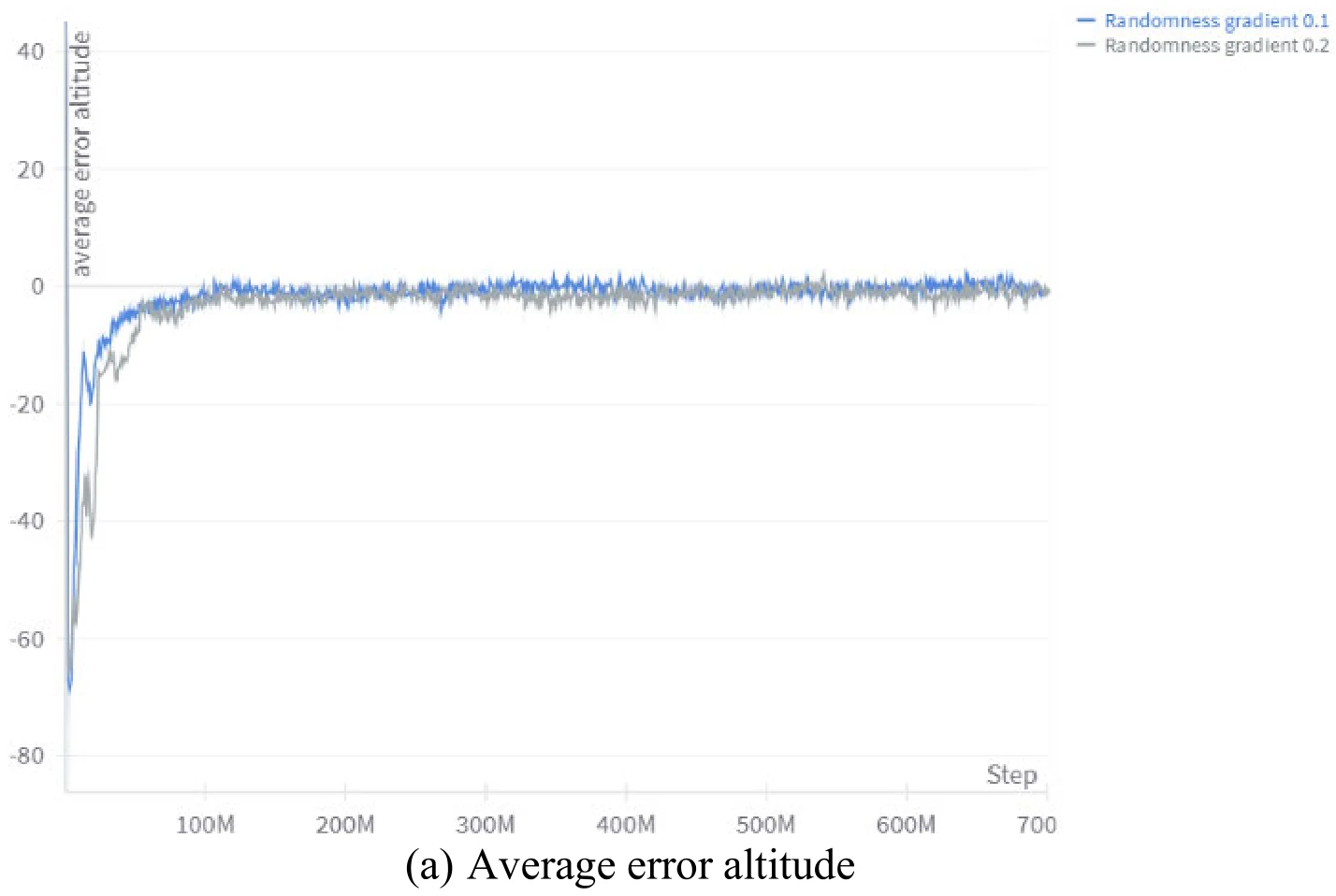
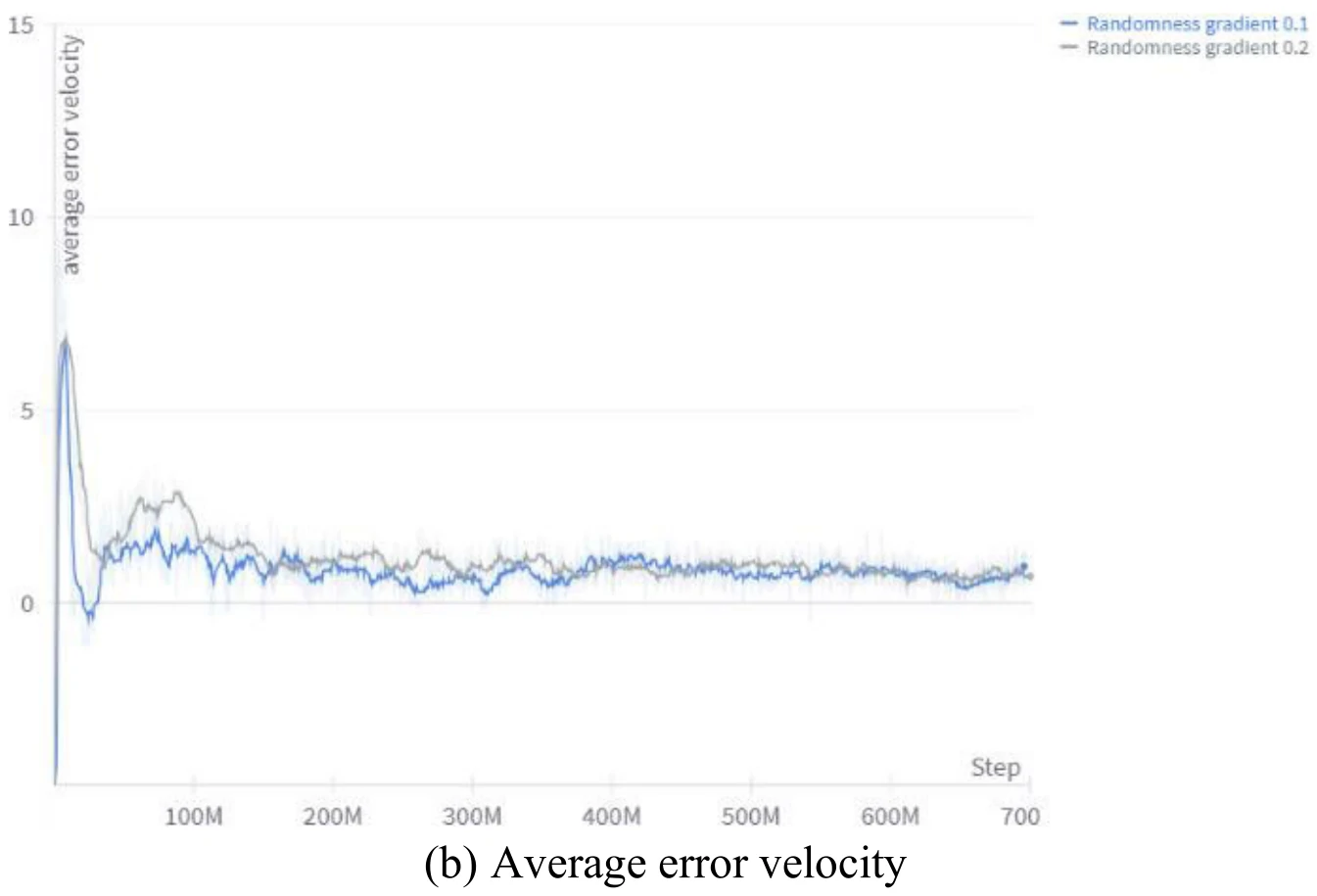
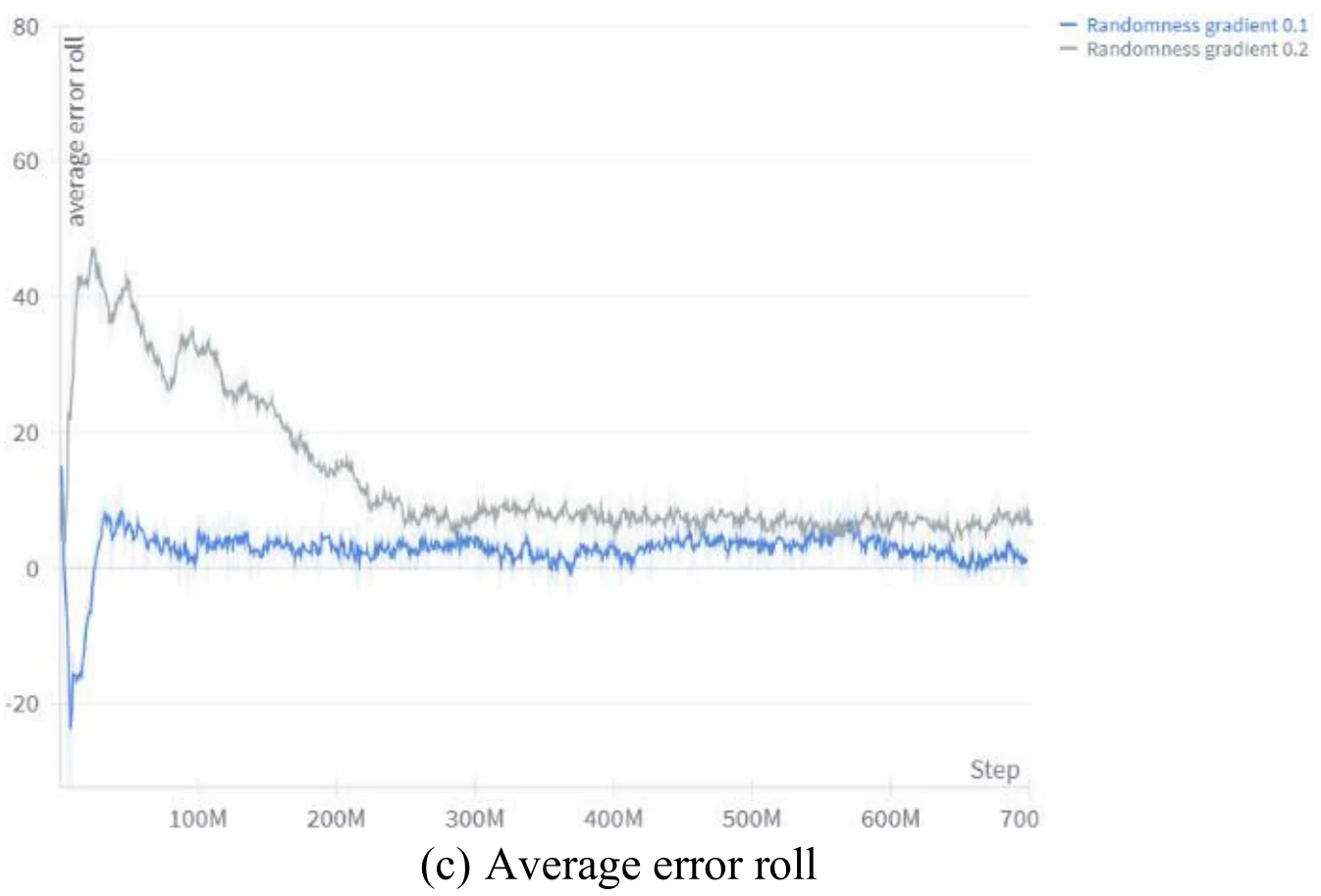
下面4张图为文章图9的4个子图,展示了目标位置随机性上升的梯度,对于训练过程中飞机与目标各个分量差异的影响。文章认为,依据图9,较小的随机性提升速度能够使训练更加稳定。
机动实验
基于上述训练结果,文章又对智能体控制飞机的能力作了一些模拟实验。
根据下文所述的实验结果,文章认为,这些实验证明了,使用文章所述方法训练的智能体能够准确地控制飞机姿态,并且能执行多种机动,展示出控制的灵活性、健壮性。
平飞(Horizontal Flight)
在本实验中:
| 符号 | 论文中的值 |
|---|---|
| 0 rad | |
| 0 rad | |
| 0 m | |
| 0 m/s |
使用这种目标设置方式来引导飞机平飞。
模拟会分为环境无风和有风进行。
下面展示了文章图10的5张子图。图10(a)展示了飞机平飞的模拟结果,图10(b)、图10(c)、图10(d)、图10(e)分别展示了飞行过程中的高度变化、偏航角变化、
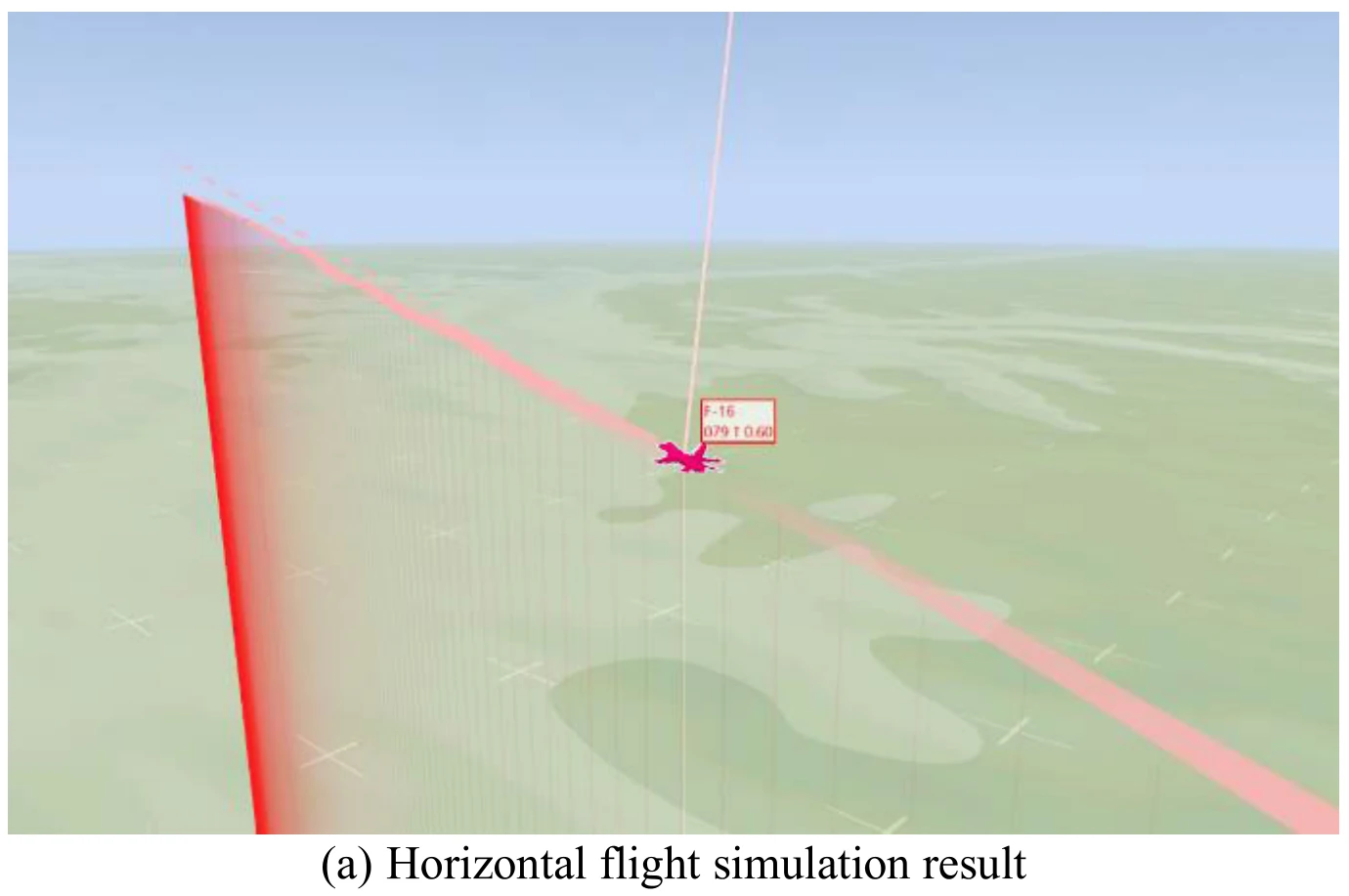
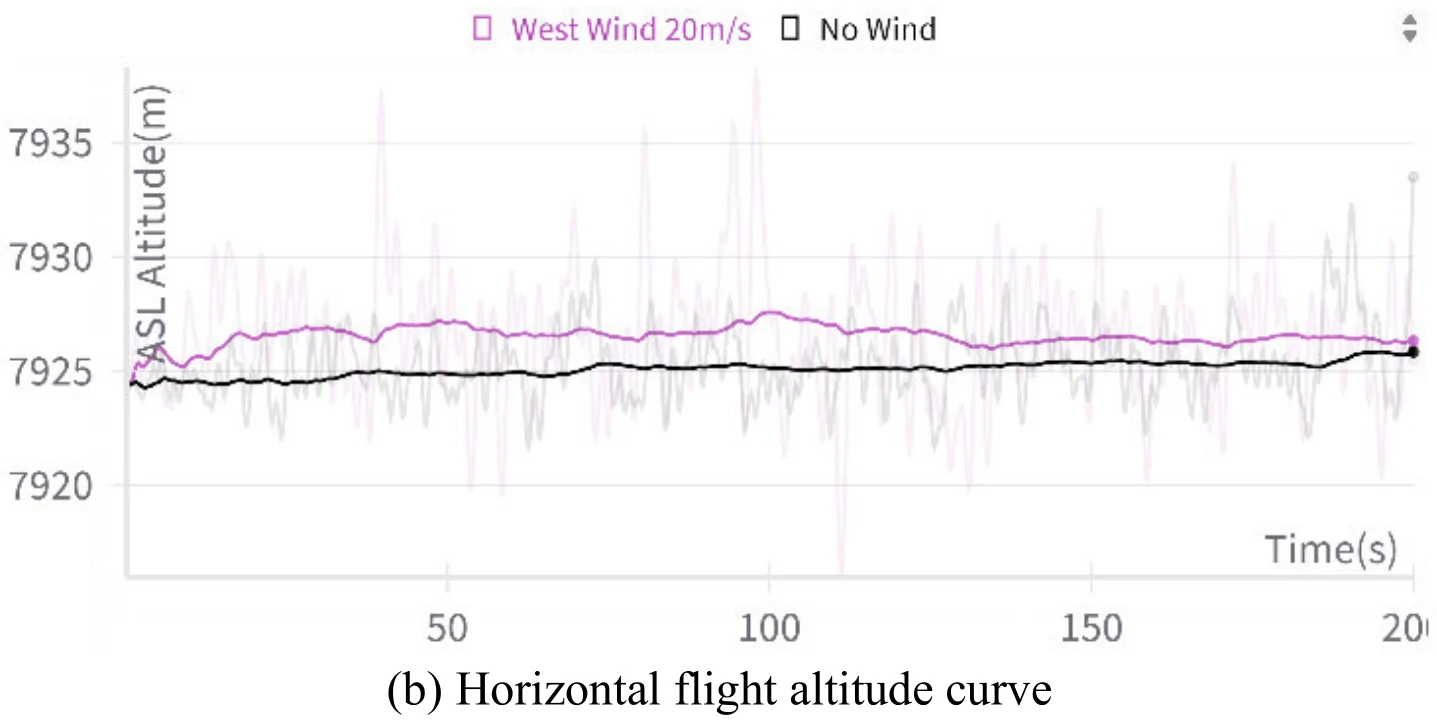
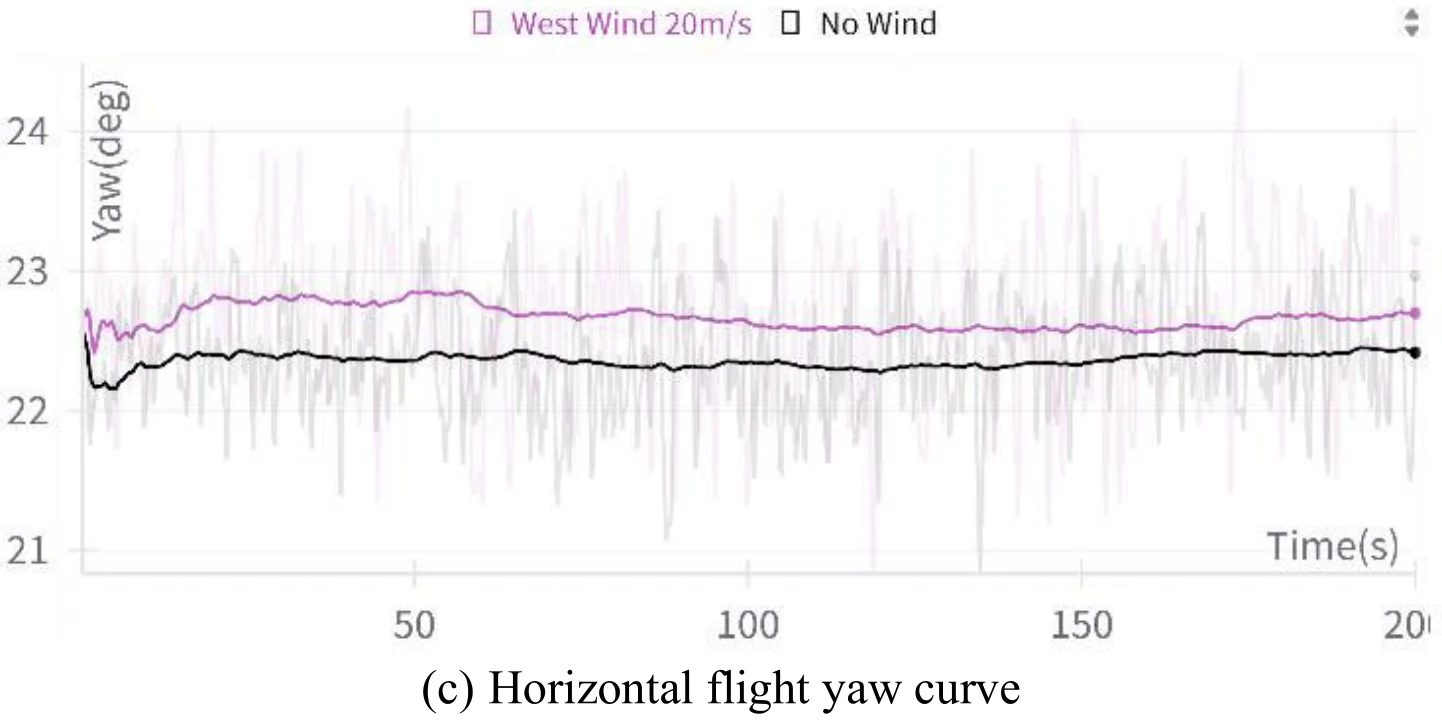
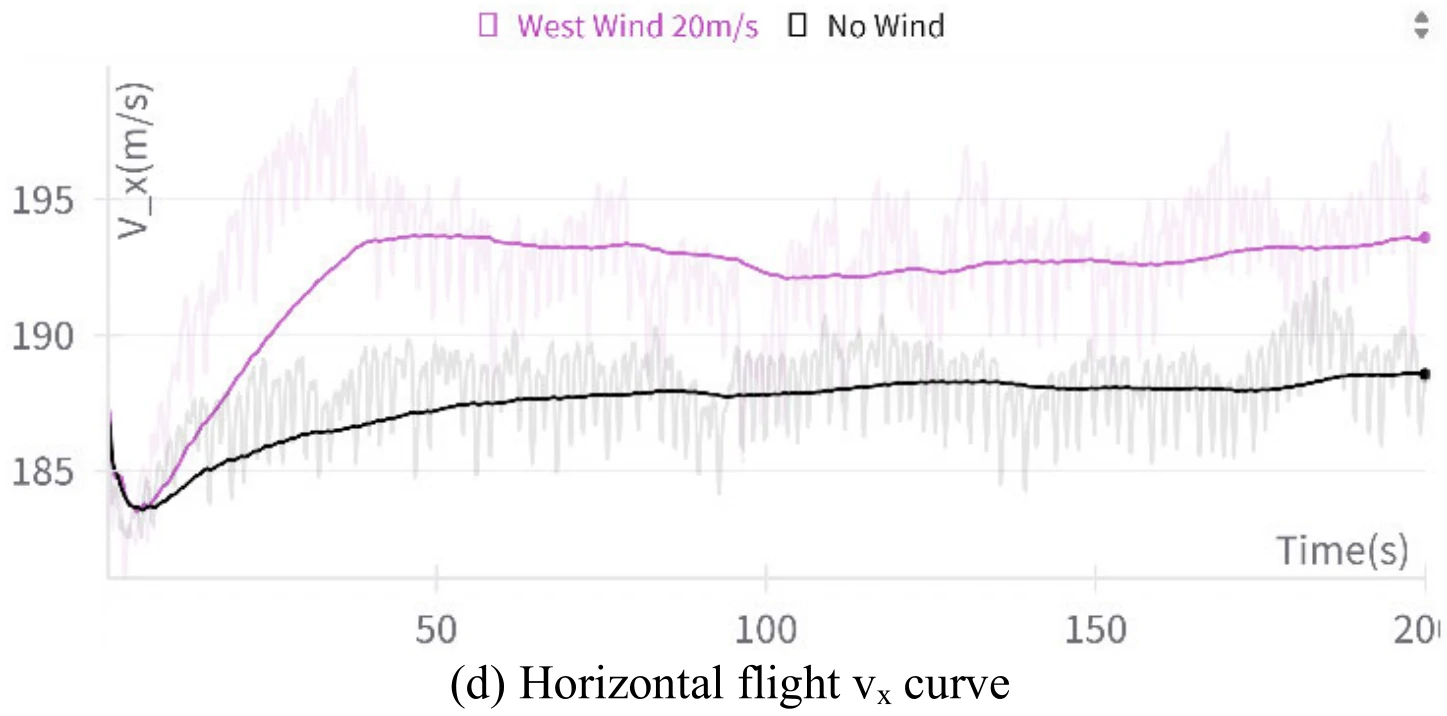
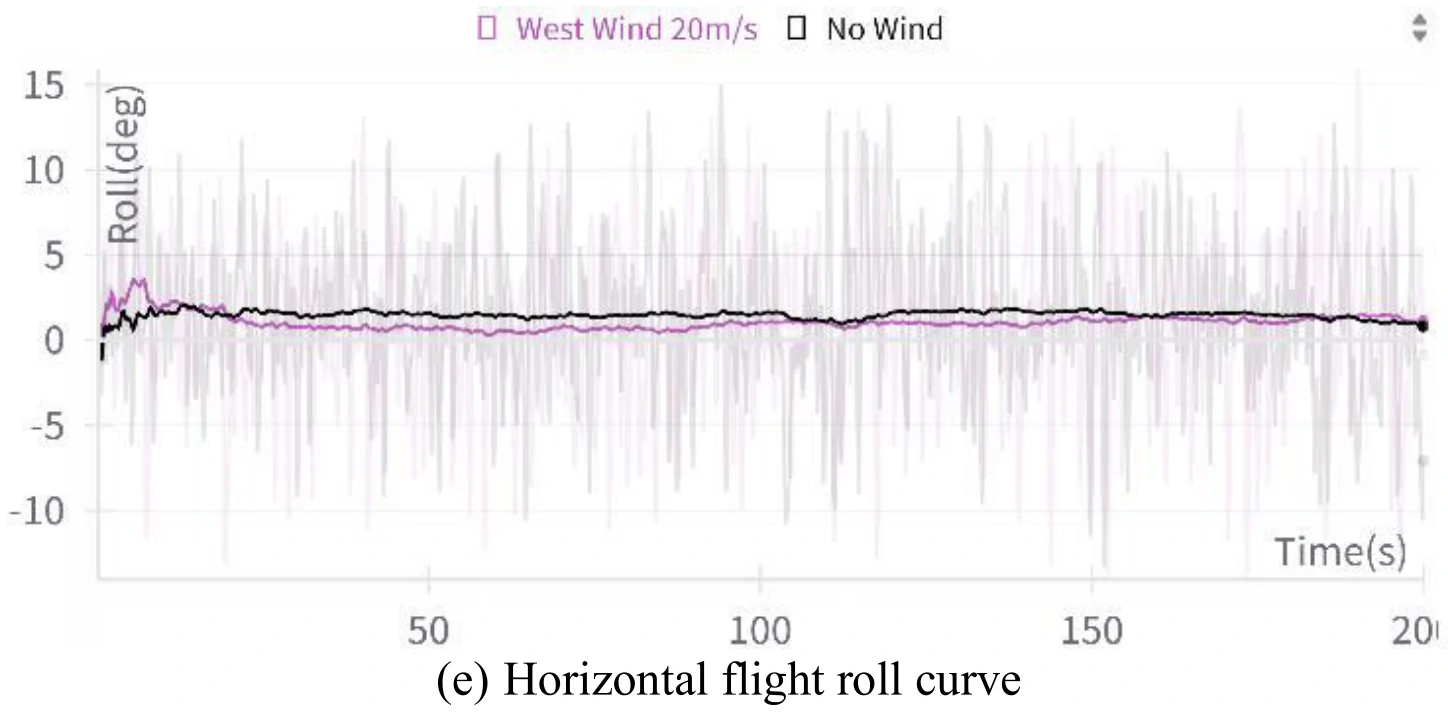
文章认为,图10展示的数据表明,即使是在强风环境下,飞机依旧能够维持平飞姿态,展示出智能体对飞机具有很稳定的控制能力。
翻滚(Looping)
在本实验中:
| 属性 | 论文中的值 |
|---|---|
| 初始高度 | 5575m |
| 初始 |
280m/s |
| 初始偏航角 | |
| 初始滚转角 |
下图展示文章图11的5张子图。图11(a)展示飞机成功地执行了翻滚机动,图11(b)、图11(c)、图11(d)、图11(e)分别展示了飞行过程中的高度变化、偏航角变化、
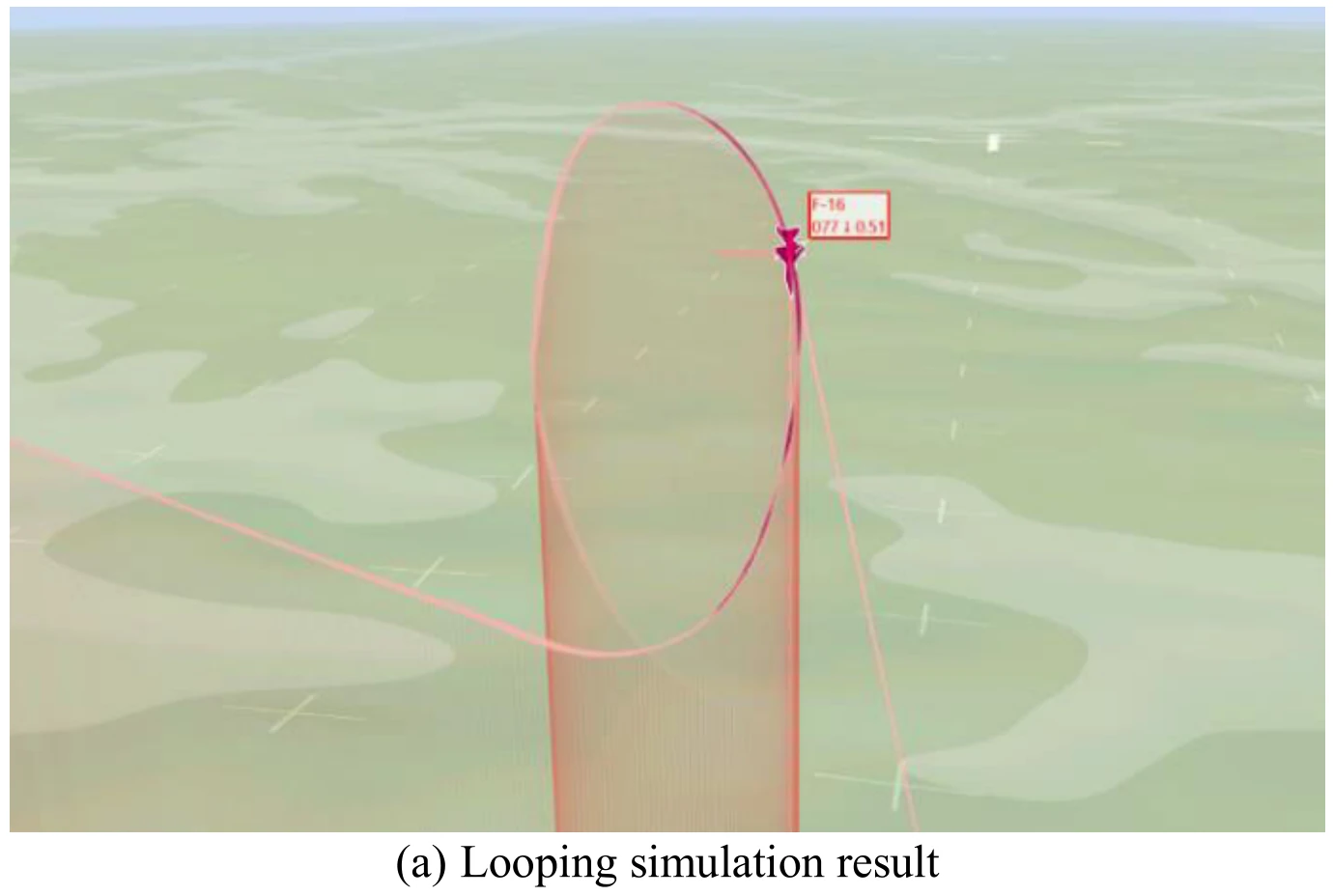
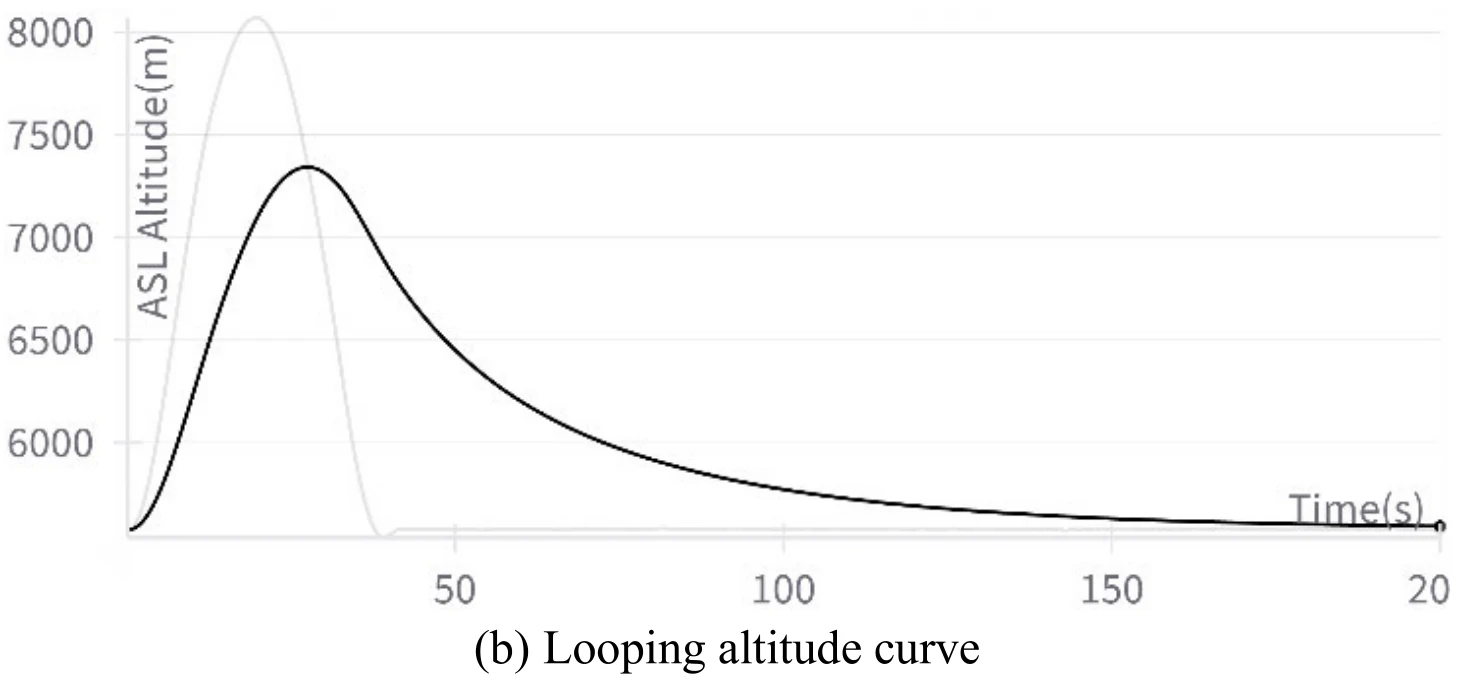
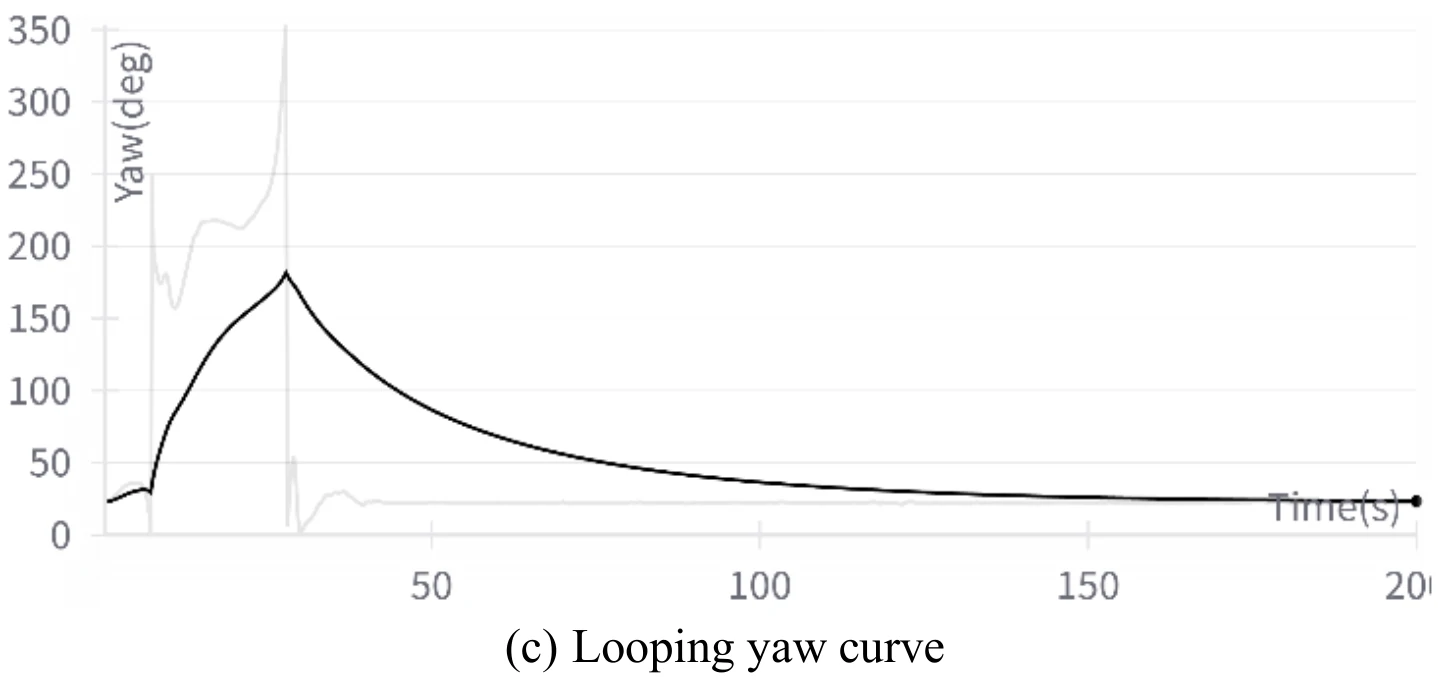
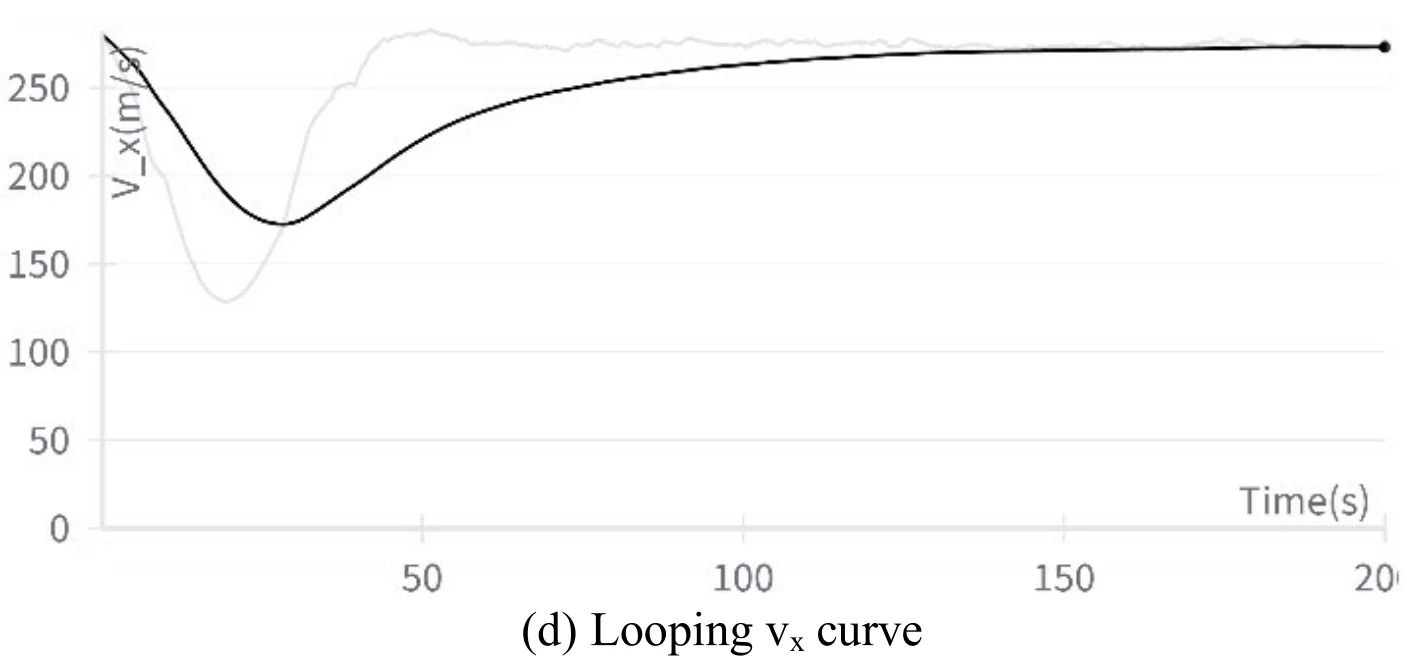
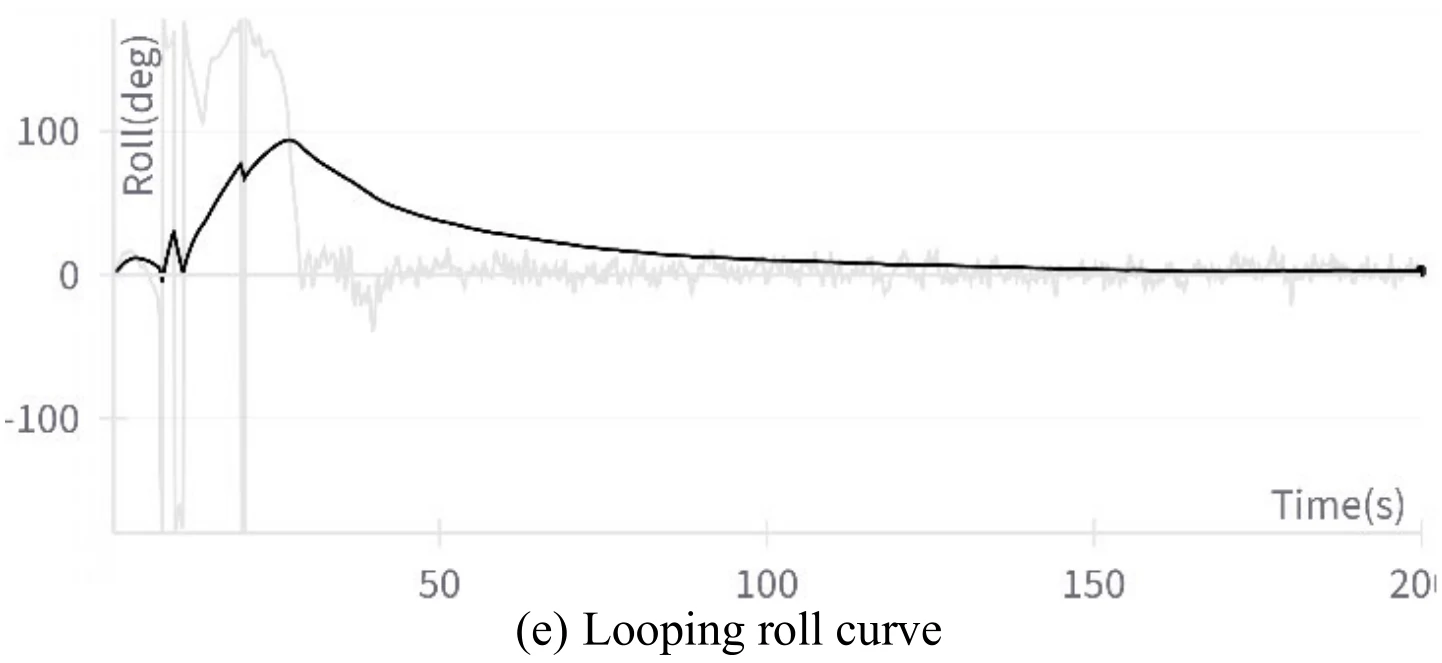
文章通过数据发现,在飞机滚转的1/4到3/4圈中,飞机的滚转角从
英麦曼回旋(Immelmann Turn)
本实验中,飞机初始状态参数与翻滚实验相同。
| 属性 | 论文中的值 |
|---|---|
| 初始高度 | 5575m |
| 初始 |
280m/s |
| 初始偏航角 | |
| 初始滚转角 |
下图展示文章图12的5张子图。图12(a)展示飞机成功地执行了翻滚机动,图12(b)、图12(c)、图12(d)、图12(e)分别展示了飞行过程中的高度变化、偏航角变化、
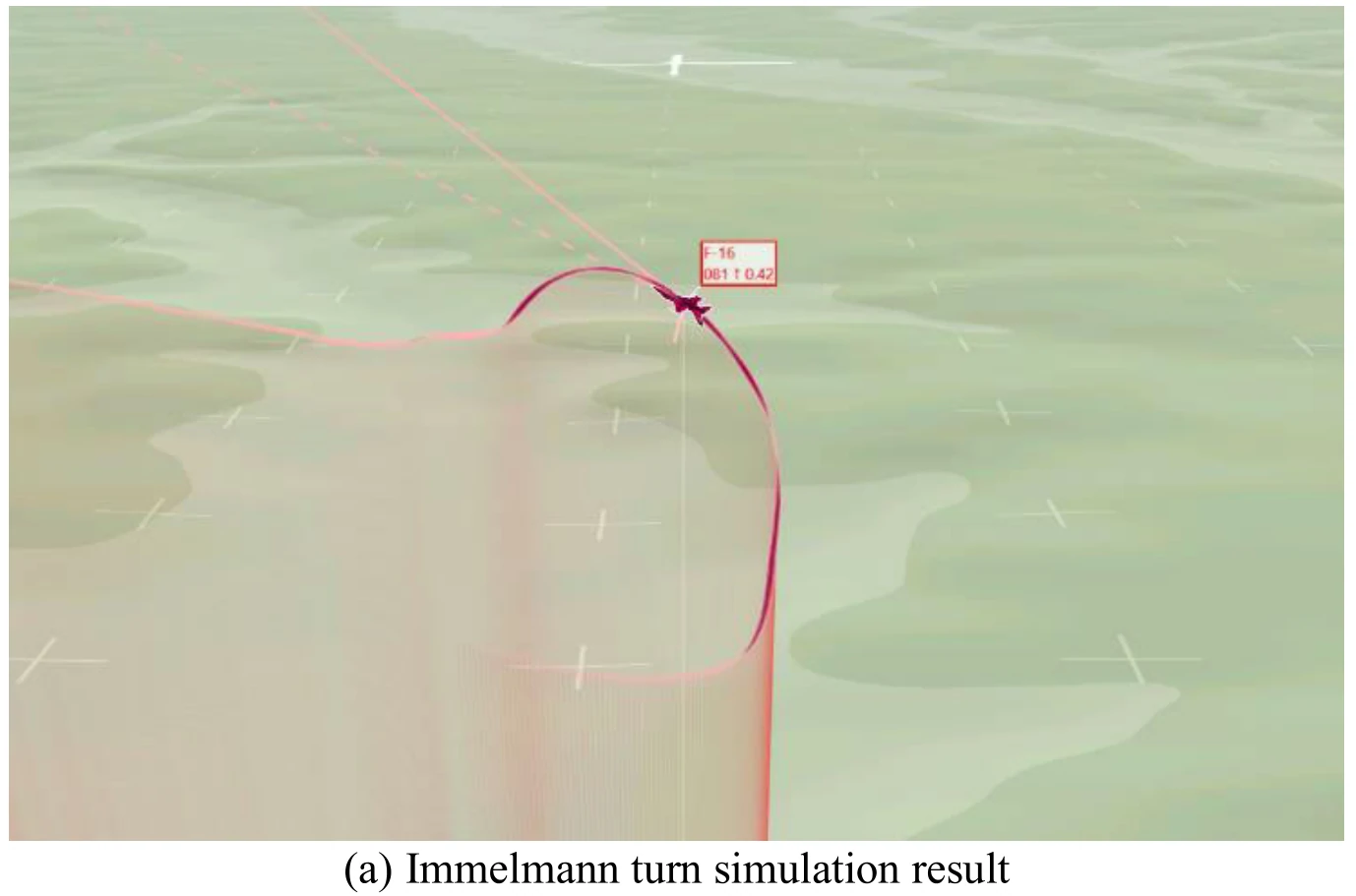
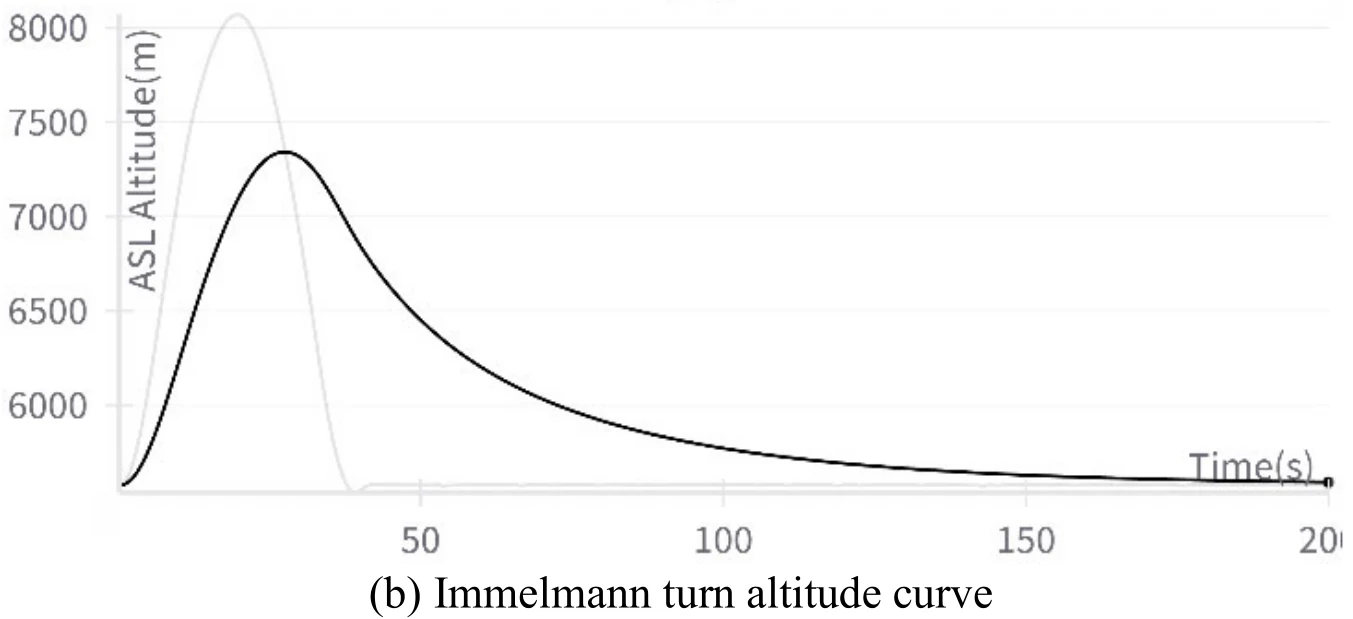
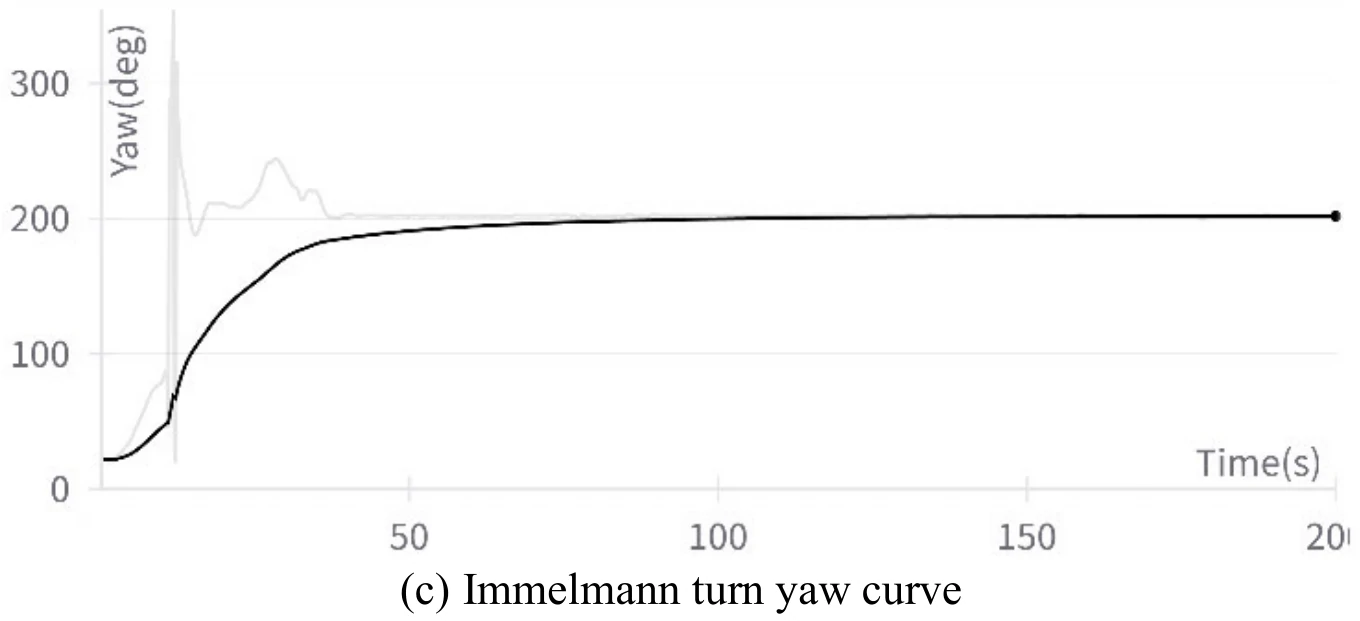
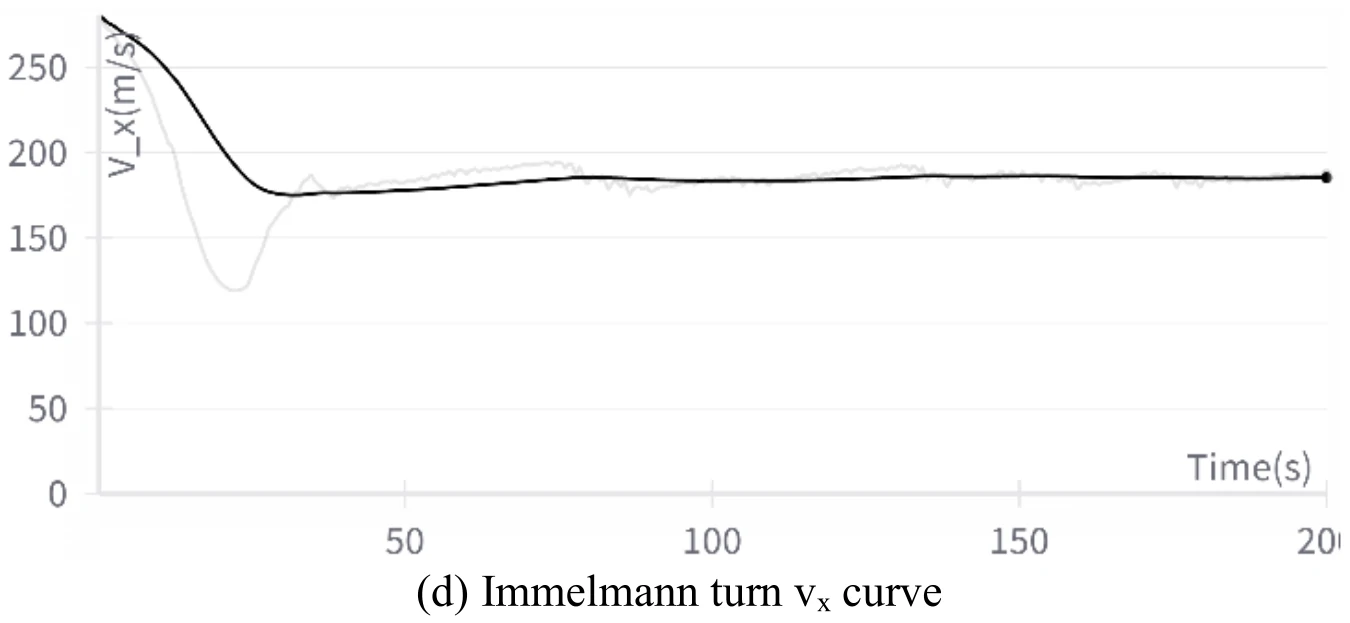
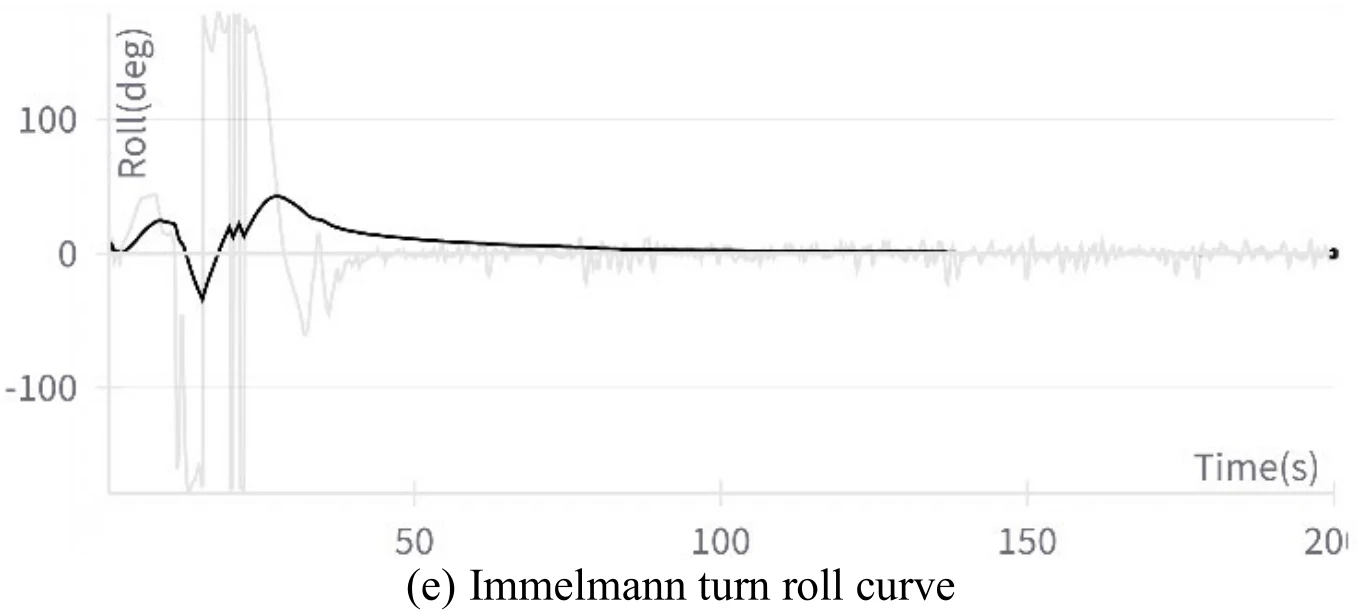
飞机在执行这个机动过程中也出现了倒飞现象。文章认为造成这一现象的原因和飞机在滚转机动中出现倒飞的原因相同。
破S(Split S)
在本实验中:
| 属性 | 论文中的值 |
|---|---|
| 初始高度 | 7924m |
| 初始 |
188m/s |
| 初始偏航角 | |
| 初始滚转角 |
下图展示文章图13的5张子图。图13(a)展示飞机成功地执行了翻滚机动,图13(b)、图13(c)、图13(d)、图13(e)分别展示了飞行过程中的高度变化、偏航角变化、
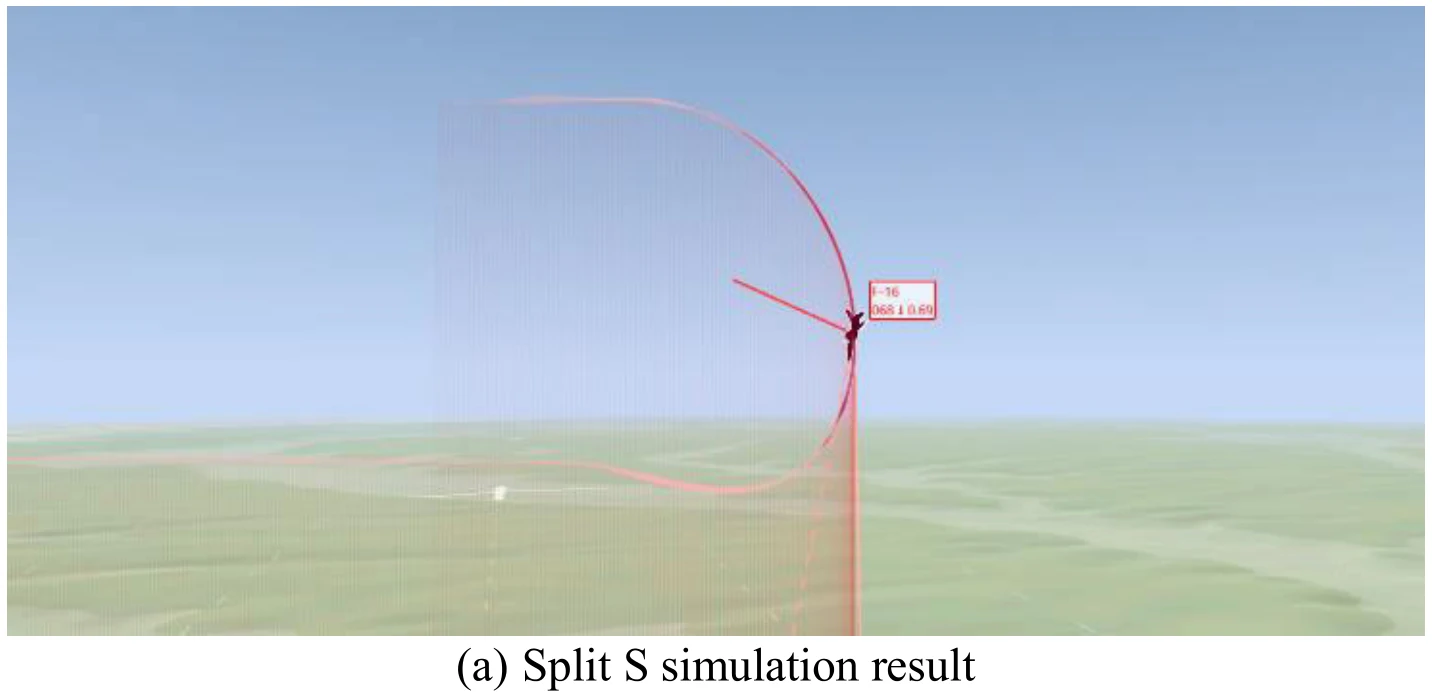
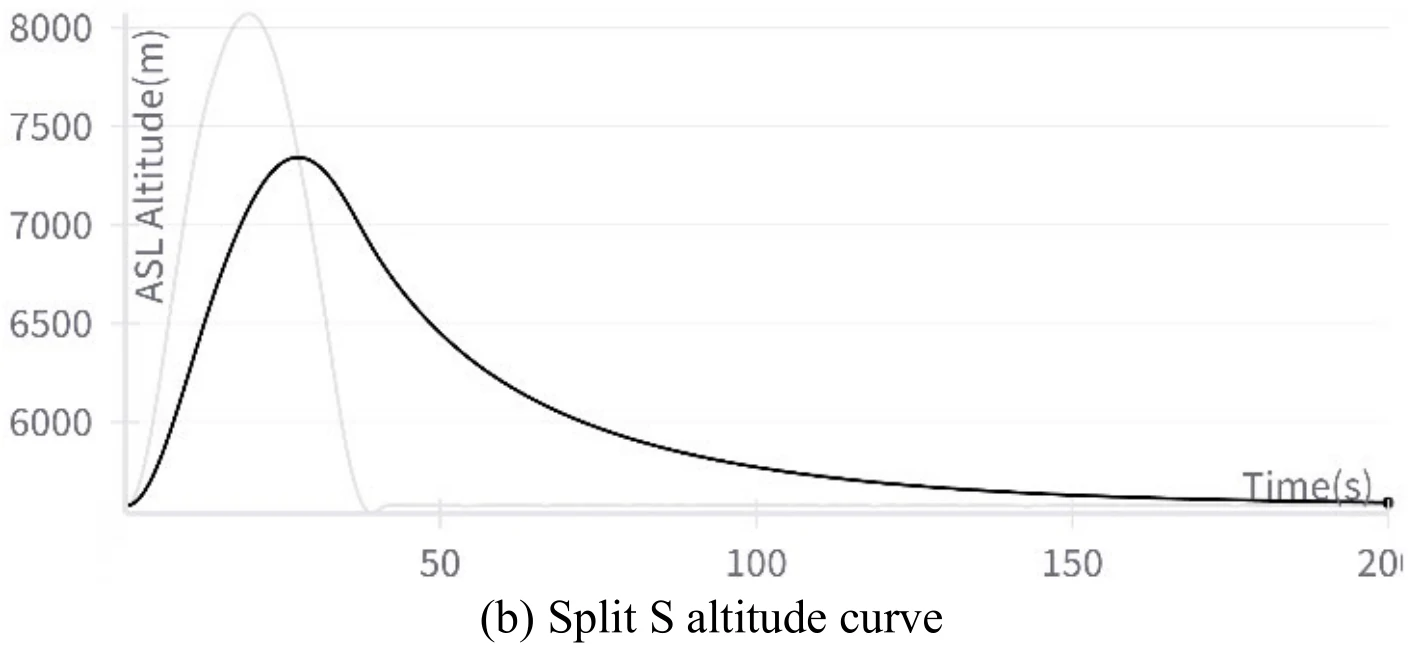
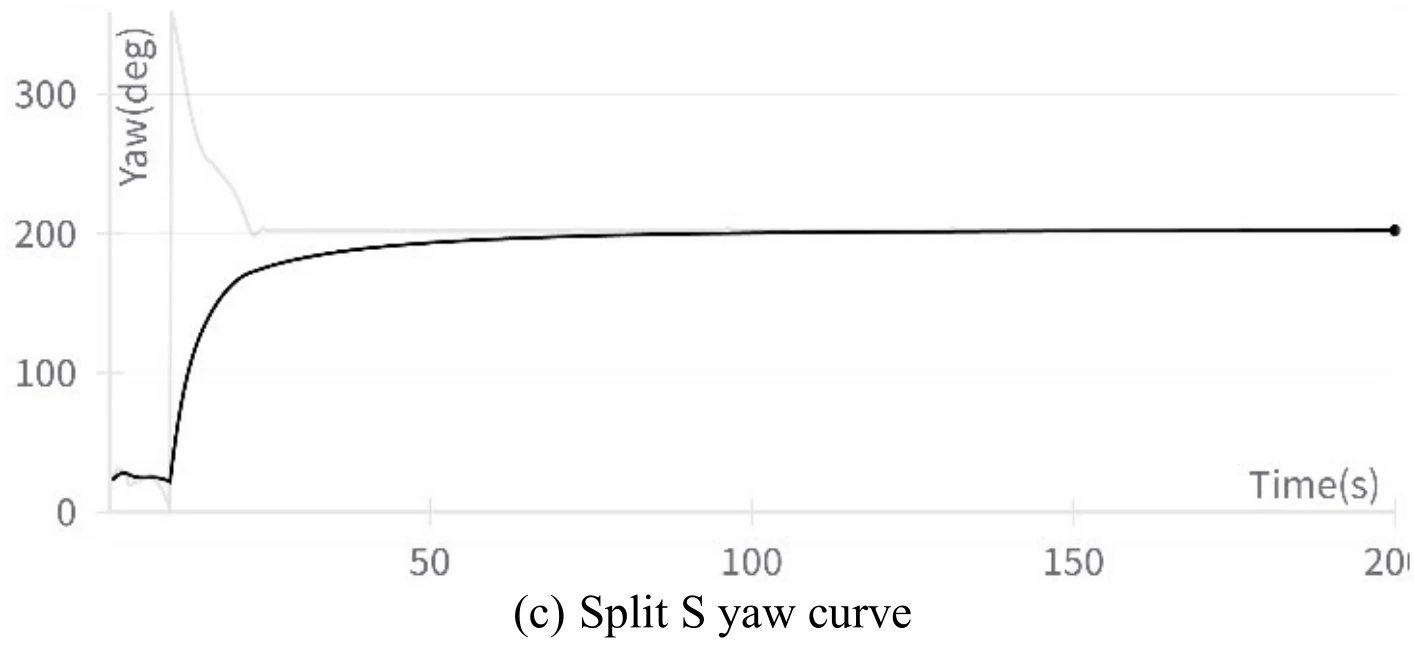
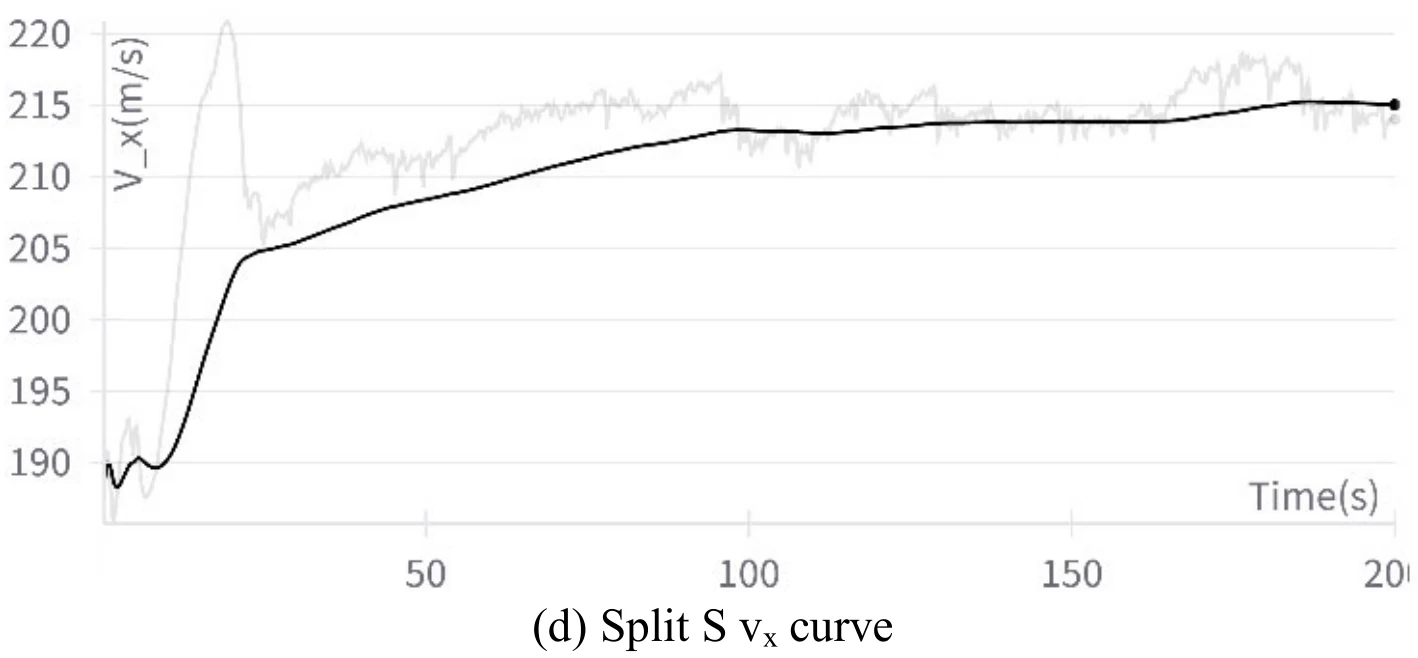
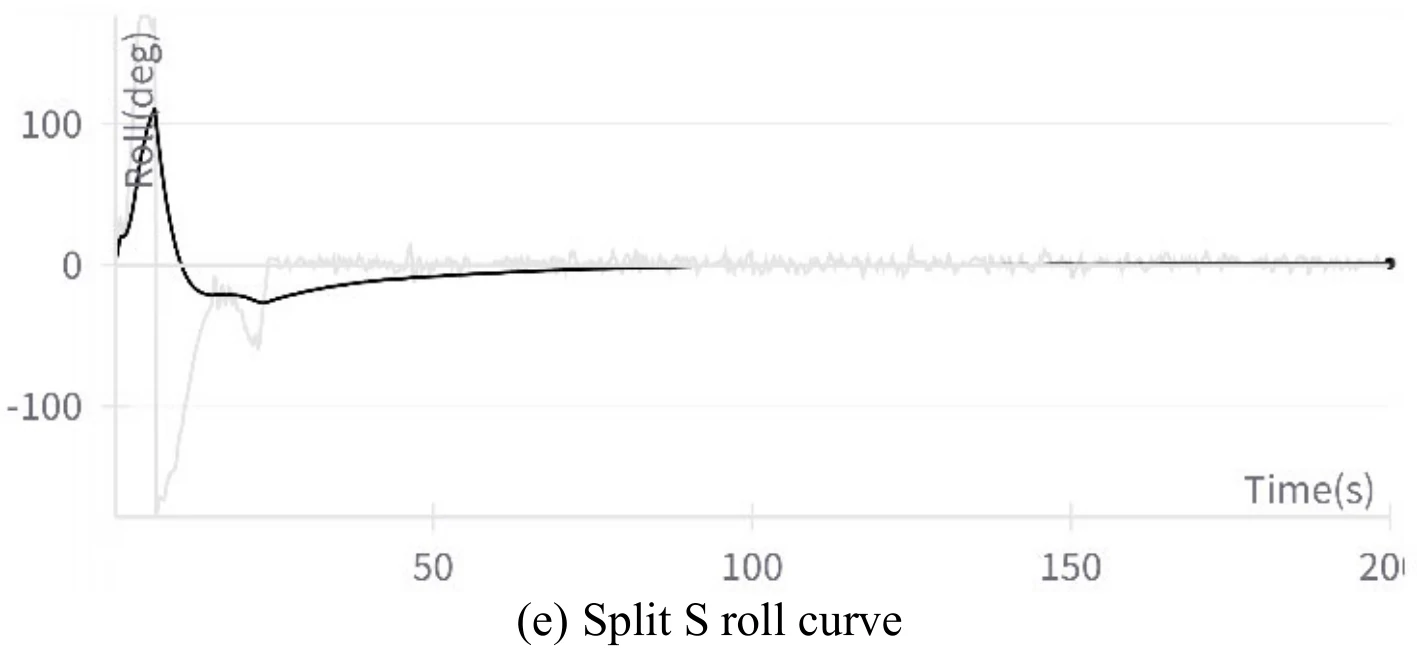
飞机滚转角数值在此机动过程中经历了从
总结
文章提出了一个LLM指导下的DRL训练框架,在LLM的指导下,训练过程中智能体探索时产生的数据质量显著提升,训练速度加快,弱化了稀疏奖励的缺陷。文中奖励函数的设计让智能体能够完成复杂的任务,逐步增长的目标设置随机性也加强了训练过程的稳定性。
文章团队之后会关注LLM与DRL在制定决策上的结合,打造一个具有可扩展性的智能空战决策系统。
读后感
文章对于LLM的使用方式比较简单,感觉LLM在文章训练框架里就起了个专家的作用,通过把智能体相对来说离谱的动作给毙掉,让智能体每次实际执行的都是合理的动作,从而提高智能体动作质量和训练过程中的奖励。
在LLM指导下,智能体每次产生动作都会交给LLM“审核”,给LLM处理的这段时间想必会增加训练所用的实际时间,至于这个问题,我目前在论文中没有看到相关陈述,文章和时间有关的内容只有训练步数,但是训练步长之类的参数在文中也没有提及。
本文是一边读文章一边写的,我在文章机动实验那一部分经历了大量的重复劳动。感觉那一部分其实只证明了一个小观点,但是篇幅很大,经常看到在不同机动章节的同一个位置、用不同的说法来阐述同一件事,有强行加字数之嫌。不过文章分析机动时提到的那个滚转角范围设置的问题挺有意思的,我之前遇到过,为了不让这些和角度有关的数值产生突变,我在把这些数值映射到状态空间时,试过把线性映射换成用三角函数映射,好处是数值不会产生突变,坏处是这种映射方法不是一一映射。不过我也没感觉出换映射方法前后,训练性能有啥改善就是了,毕竟都坠机了,man!
